由于实习工作的需要,需要使用Kafka+Druid+grafana,将kafka数据导入到Druid并使用grafana进行数据的可视化,在这里记录下Druid的学习笔记。(注:这里的Druid不是阿里的那个druid数据库连接池,这两个是完全不一样的东西,这里的Druid仍然是apache开源的)
什么是Druid
Druid是一个高效的数据查询系统,主要解决的是对于大量的基于时序的数据进行聚合查询。数据可以实时摄入,进入到Druid后立即可查,同时数据是几乎是不可变。通常是基于时序的事实事件,事实发生后进入Druid,外部系统就可以对该事实进行查询。
Druid具有快速查询、水平扩展能力以及实时分析的特点,Druid数据吞吐量大、支持流式数据摄入、查询灵活且快。Druid是一个分布式系统,采用Lambda架构(关于Lambda架构可以看这篇博客用于实时大数据处理的Lambda架构),将实时数据和批处理数据进行解耦。整个分布式系统采用shared nothing的结构,每个节点都有自己的计算和存储能力,整个系统使用zookeeper进行协调,另外还有使用Mysql用于元数据的存储。
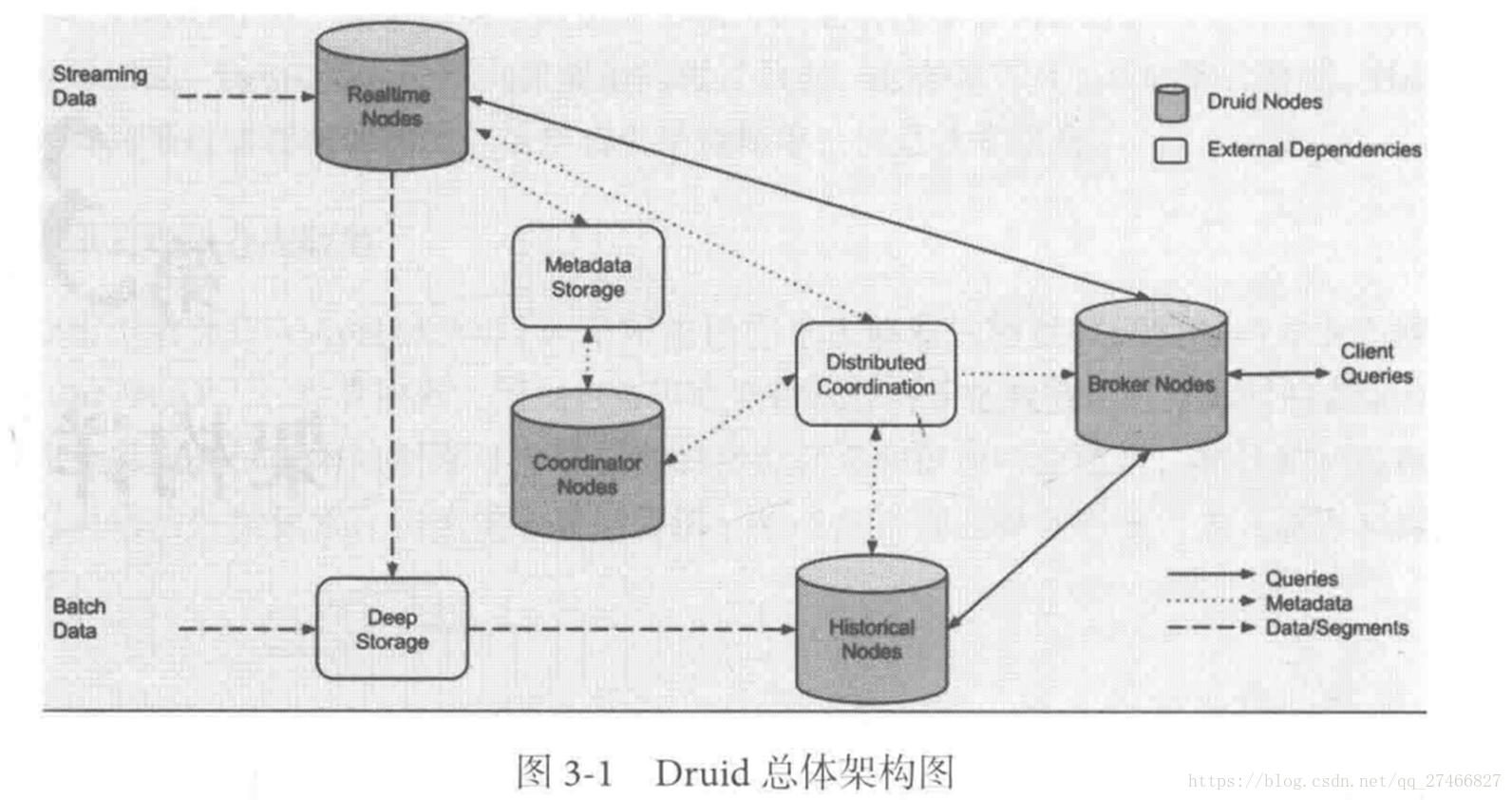
Druid节点
Druid内部节点
- Historical Node:历史节点的职责主要是对历史的数据进行存储和查询,历史节点从Deep Storage下载Segment,然后响应Broker对于Segment的查询将查询结果返回给Broker节点,它们通过Zookeeper来声明自己存储的节点,同时也通过zookeeper来监听加载或删除Segment的信号。
- Realtime Node:实时节点用于摄入实时数据,以及生成Segment数据文件。
- Broker Node:查询节点接收外部客户端的查询,并且将查询路由到历史节点和实时节点。当Broker收到返回的结果的时候,它将结果merge起来然后返回给调用者。Broker通过zookeeper来感知实时节点和历史节点的存在。
- Coordinator Node:协调节点负责历史节点的数据负载均衡。协调节点读取元数据存储来确定哪些Segment需要load到集群中,通过zk来感知Historical节点的存在。
Druid外部节点
- MetaStore:用于存储Druid集群的元数据信息,比如Segment相关元信息,一般是用Mysql或者其他数据库
- Zookeeper:负责协调Druid内部节点
- DeepStorage:存放生成的segment数据文件,并供历史节点下载,一般是用HDFS。
Druid数据结构
对于摄入到Druid的数据的列,主要分三种类型,时间列,指标列和维度列。如下
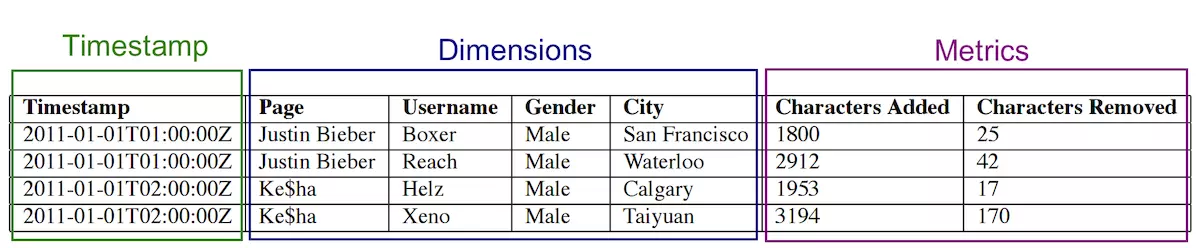
Druid的数据是按列存储的,每一列的所有数据都存储在一段连续的文件地址内,执行查询的时候只需要访问相关的列即可,而且由于列内数据的存储地址是连续的,所以读取每一列的数据都很快。
对于维度列来说,每个维度列需要下面三个数据结构
- 一个map,Key是维度的值,值是一个整型的id
- 一个存储列的值得列表,用1中的map编码的list
- 对于列中的每个值对应一个bitmap,这个bitmap用来指示哪些行包含这个个值。
对于上面Page这个维度列,它的存储结构是这样的
1: 字典
{
"Justin BIeber": 0,
"Ke$ha": 1
}
2. 值的列表
[0,
0,
1,
1]
3. bitMap
value="Justin Bieber": [1, 1, 0, 0]
value="Ke$ha": [0, 0, 1, 1]
Realtime Node
在这篇博客中简述了LSM大致的原理,通过这篇博客可以了解到LSM是适用于数据插入操作远多于更新、删除与读操作的,而Druid在一开始就是为时序数据场景设计的,因此在Druid的架构中,也存在着LSM的思想。
结合Druid内部节点所讲到的节点以及LSM的思想,下面说下Segment文件的产生和传播。
Druid的Realtime Node负责消费实时数据,与LSM不同的是,LSM在写入数据前会有WAL操作,而Druid并不提供日志和WAL,实时数据首先会被直接加载到Realtime Node内存中的缓冲区,当满足一定条件时,缓冲区的数据会被写到硬盘上,形成一个数据块(Segment Split),Realtime Node同时会周期性地将磁盘上同一个时间段内生成的所有Segment Split合并成一个Segment,这个过程LSM中也有出现过,Segment文件的相关元数据信息会保存到MetaStore中(如mysq),合并完的Segment会上传到DeepStorage中。
Coordinator Node从MetaSotre中获取到Segment数据文件的相关元信息后,将按配置的规则分配到符合条件的Historical Node中。Historical Node收到协调节点的通知后,会从DeepStorage中拉取该Segment数据文件,并通过zookeeper向集群声明可以提供查询了。实时节点会丢弃该Segment数据文件,并通过zookeeper向集群声明不再提供该Segment的查询服务。
Historical Node
历史节点负责加载生成好的Segment文件以提供数据查询,由于Druid中的数据是不可更改的,因此Historical Node的任务就是专注于提供数据查询。
Historical Node在启动的时候,首先会检查自己的本地缓存,然后从DeepStorage中下载属于自己但不在自己本地磁盘的Segment文件。无论是什么查询,Historical Node都会首先将相关Segment文件从磁盘加载到内存,然后再提供查询服务。
从上面可以看到,内存的大小很大程度决定了数据查询的效率,为了解决硬件的异构性以及数据温度的问题,Druid提出了层(Tier)的概念,将集群中所有Historical Node根绝性能容量分为不同的层,并且让不同性质的DataSource使用不同的层来存储Segement文件,以达到效率与成本相对平衡的状态。
Broker Node
查询节点对外提供数据查询服务,由于数据存在于Realtime Node与Historical Node中,因此Broker Node还需要把从两者查询到的数据进行合并,合并后返回给调用方。
Broker Node中会使用缓存来存储之前的查询结果,一般一个Druid集群中只需要一个Broker Node即可,但为了防止单点故障问题,同时也为了实现负载均衡,因此在实践中会多加几台Broker Node,达到高可用的效果。
Coordinator Node
协调节点负责历史节点的数据负载均衡,以及通过规则管理数据的生命周期。
Druid不像HDFS或者Yarn这些采用Master-Slave架构,在Druid中并没有真正意义上的Master节点。但是对于Historical Node节点而言,Coordinator Node相当于它们的Master节点,虽然Historical Node对外提供数据查询并不直接受制于Coordinator Node,但是如果Coordinator Node节点无法提供服务的话,Historical Node虽然还能够提供查询服务,但是无法再接收新的Segment数据了。
Druid可以对每个DataSource设置规则(Rule)来加载(load)或者丢弃(drop)具体的Segment文件,对于一个DataSource,可以添加多条规则,Coordinator Node会对每个Segment文件逐个用规则进行判断,如果符合load或者drop条件,立刻执行load或者drop操作,并停止检查剩下的规则,否则继续检查下一条设置好的规则。
索引服务
上面讲到了,可以通过Realtime Node生成Segment文件,除此之外,Druid还提供了索引服务,也能够生成Segment文件,与Realtime Node不同的是,除了能够对数据使用pull的方式外,还支持push的方式,不同于手工编写数据消费配置文件的方式,可以通过API编程方式灵活定义任务配置,可以更灵活地管理与使用系统资源,可以完成Segment副本数量的控制,还能够完成Segment文件的相关操作如删除、合并等。
索引服务的架构也是Master-Slave,统治节点(Overlord Node)为主节点,中间管理者(Middle Manager)为从节点。
Overlord Node对外负责接收任务请求,对内负责把任务分解并下发到Middle Manager上。
Overlord Node节点有两种运行方式:
- 本地模式(Local Mode):默认情况下是该模式,该模式下,Overlord Node不仅负责任务分发,还负责启动一部分苦工(peon)来完成一部分具体的任务
- 远程模式(Remote Mode):该模式下,Overlord Node和Middle Manager在不同的节点上,Overlord Node仅负责任务协调分配,不负责完成任务具体的任务。
Overlord Node、Middle Manager和peon可以类比于Yarn中的ResourceMangaer、NodeManager和Container
引用: