LL(1)文法
在前面讲到的递归下降分析过程中,有可能会出现回溯,回溯的出现会导致分析的速度下降,如果能在每一步过程中准确判断出选择哪个产生式的话,就不需要回溯。 这种分析叫做预测分析技术。LL(1)文法就适用于预测分析方法。
在说明LL(1)文法之前,先说下一些简单的文法
S_文法(简单的确定性文法)
满足以下两个要求:
1、每个产生式的右部都以终结符开始
2、同一非终结符的各个候选式的首终结符都不同
满足这两个要求的文法,在推导过程中,每一步都能唯一地确定要使用哪个产生式。
非终结符的后继符号集(follow集)
非终结符A的后继符号集指的是,可能在某个句型中紧跟在A后边的终结符a的集合(不包括ε ),该集合记为FOLLOW(A)
产生式的可选集
产生式A —> $\beta$的可选集是指可以选用该产生式进行推导时对应的输入符号的集合,记为SELECT(A —> $\beta$)
SELECT( A→aβ ) = { a } SELECT( A→ε )=FOLLOW( A )
q_文法
每个产生式的右部或为ε ,或以终结符开始
具有相同左部的产生式有不相交的可选集(SELECT集)
注:q_文法不含有右部以非终结符开头的产生式。
串首终结符集
定义:给定一个文法符号串a,a的串首终结符集FIRST(a)被定义为可以从a推导出的所有串首终结符构成的集合
结合上面FOLLOW集和SELECT集的概念,可以得到
如果 ε$\notin$FIRST(α), 那么SELECT(A→α)= FIRST(α)
如果 ε∈ FIRST(α), 那么SELECT(A→α)=( FIRST(α)-{ε} )∪ FOLLOW(A)
下面给出LL(1)文法的定义
文法G是LL(1)的,当且仅当G的任意两个具有相同左部的产生式A → α | β 满足下面的条件:
如果α 和β均不能推导出ε ,则FIRST (α)∩FIRST (β) =Φ
α 和β至多有一个能推导出ε
如果 β =>* ε,则FIRST (α)∩FOLLOW(A) =Φ;
如果 α =>* ε,则FIRST (β)∩FOLLOW(A) =Φ;
同一非终结符的各个产生式的SELECT集互不相交
注:这个定义可能不好理解,可以看完下面的例子然后再回过头来琢磨
LL(1)文法就是根据各个产生式的SELECT集来预测下一步
SELECT集的运算过程如下
首先先计算出FIRST集
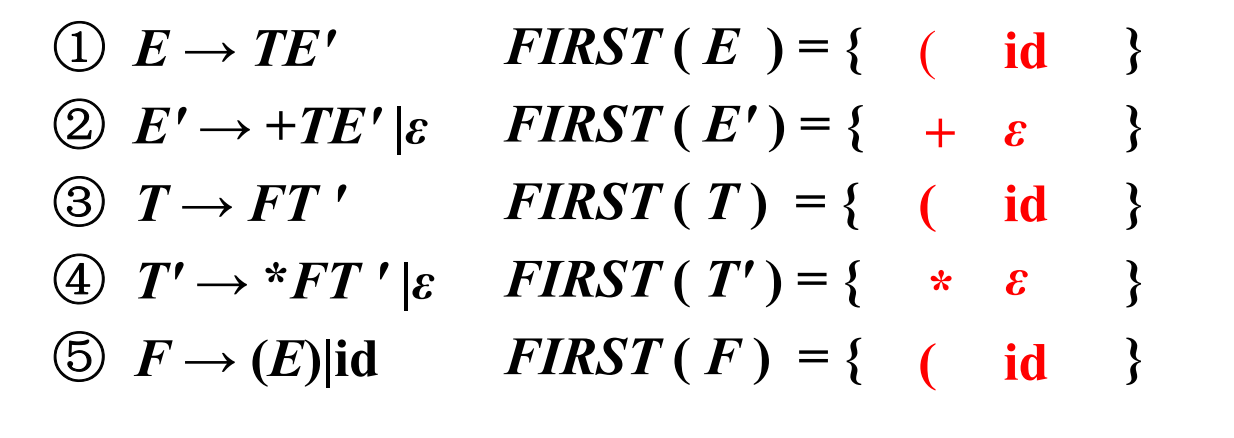
然后计算出FOLLOW集

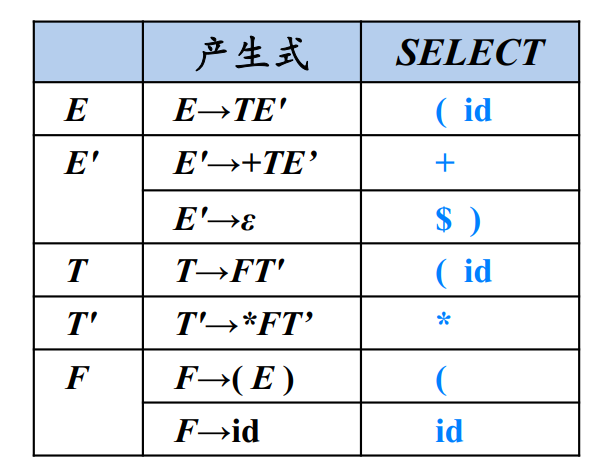
最后计算SELECT集

根据SELECT集构造预测分析表
说到底,这些预测方法的实现最终还是得落实到代码上,也就是说,这些预测都是得交由代码来实现,LL(1)文法的实现有两种,一种是递归的预测分析法,一种是非递归的预测分析法。
递归的分析法就是根据开始符号集,对于每个读入的单词,为每个非终结符和终结符写出其对应的判断代码

如上图左边这个文法,开始符号集是<PROGRAM>,通过右边的伪代码可以知道,首先根据开始符号的SELECT集可以得出,该文法的第一个单词是program,根据第一个单词确定是否要继续往下执行,如果继续往下执行的话,根据开始符号集的产生式的右部,结合上推断出的FOLLOW集,对每个单词进行逐一的判断。DECLIST方法的实现伪代码如下,

其他方法的实现也与其类似,这里就不再粘贴:)
可以看到递归实现的好处就是比较直观,但是代码量比较大
下面看看非递归的预测分析法
非递归的预测分析法不需要为为每个非终结符编写其判断的方法,而是根据预测分析表,构造一个下推自动机(这里下推自动机实现的数据结构使用的是栈)
算法过程如下:
算法开始时,栈里面有两个元素$和开始符,定义一个指针指向输入串的开始,根据栈顶元素和当前指针所处的位置的字符,以及预测表进行判断,有以下几个步骤:
1、如果当前栈顶仅剩元素$,且指针到达字符串的末尾,则代表已经匹配完成,算法结束,否则进入步骤2
2、如果当前栈顶的终结符等于指针所处位置的字符,则代表当前字符已经匹配,元素出栈,指针后移,返回步骤1,否则进入步骤3
3、如果当前栈顶的终结符不等于指针所处位置的字符,则代表匹配失败,算法结束,否则进入步骤4
4、如果当前栈顶是非终结符,则根据预测表,把栈顶元素换成对应预测表中的产生式右部,进入步骤2,如果栈顶元素和当前字符在预测表中没有对应的产生式,则代表匹配失败,算法结束
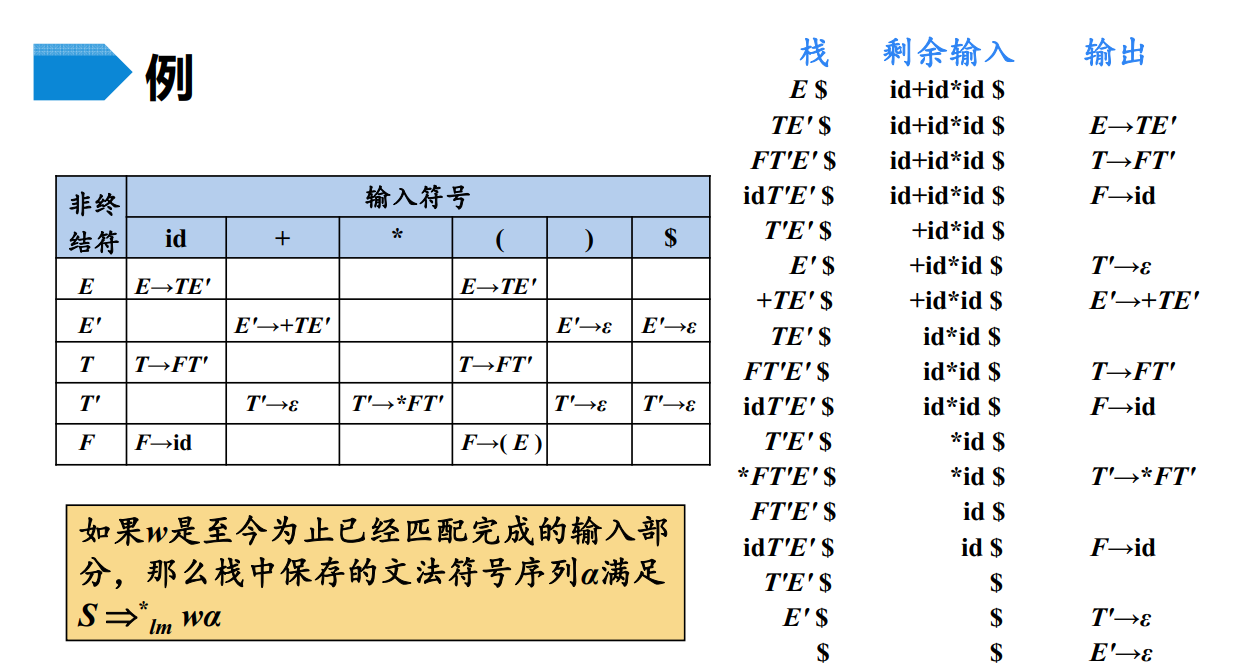
非递归预测分析和递归预测分析的对比
| 递归预测分析法 | 非递归预测分析法 | |
|---|---|---|
| 程序规模 | 程序规模较大,不需载入分析表 | 主控程序规模较小,需载入分析表(表较小) |
| 直观性 | 较好 | 较差 |
| 效率 | 较低 | 分析时间大约正比于待分析程序的长度 |
| 自动生成 | 较难 | 较易 |
预测分析法实现步骤
1、构造文法
2、改造文法:消除二义性、消除左递归、消除回溯
3、求每个变量的FIRST集和FOLLOW集,从而求得每个候选式的SELECT集
4、检查是不是 LL(1) 文法。若是, 构造预测分析表
5、对于递归的预测分析,根据预测分析表为每一个非终结符编写一个过程;对于非递归的预测分析,实现表驱动 的预测分析算法