shuflle过程
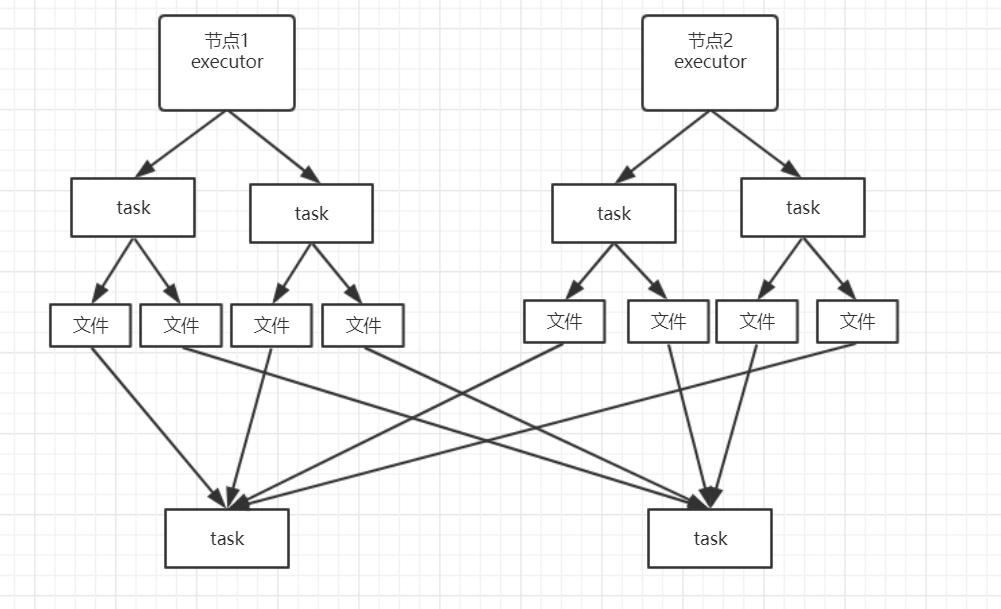
上图是shuffle的基本过程,在map端,每个task会输出和下个stage相同task数量的文件,然后reduce端每个task会从map端拉取属于自己task的文件。
看似没有问题,但是设想在真正在生产环境中,假设现在有100个节点(每个节点只有一个executor),每个节点2个core,map端和reduce均是1k个task,平均每个executor一共处理10个task。
现在每个节点需要输出10*1k=1w个文件
map端一共有100*1w=100w个文件
在map端上的一个任务就会产生大量的输出文件
map端文件合并
通过下面的参数开启map端文件合并
new SparkConf().set("spark.shuffle.consolidateFiles", "true")
开启map端文件合并后,之后每一轮执行的task输出时不会产生新的文件,而是回去寻找上一轮task的输出文件进行复用,把内容追加进去。
上面的例子在开启该参数后,map端的输出文件个数变成了20w。
map端内存缓存和reduce端内存缓存
上图中map端task输出文件时,并不是直接写入到磁盘中,而是先把结果输出到内存缓冲区中(大小为32kb),当缓冲区满了之后,才会溢写(spill)到磁盘中。
reduce端同样也有内存缓冲区,reduce在拉取上一个stage的文件时,以HashMap的形式把数据进行汇聚,然后再进行聚合操作,该过程使用的是executor的内存,默认executor划分给reduce task的比例是0.2,如果缓冲区满了,reduce也是会溢写到磁盘中。
在处理数据量比较大的情况下,map端将会产生大量的溢写操作,发生大量的磁盘IO,降低性能。
同理,在处理大量数据的时候,reduce端在汇聚数据的时候,也会大量溢写,还有,溢写的数据量越多,在后面进行聚合操作的时候(比如reducebykey(_+_)),会多次读取磁盘文件。
spark.shuffle.file.buffer//调节map task内存缓冲,默认32k
spark.shuffle.memoryFraction//调节reduce端聚合内存占比,0.2
增加这两个参数可以减少map溢写次数,也能够减少reduce溢写次数,还能减少reduce聚合操作时读取文件的数量。(注,但也不能一直增加,因为这里如果占用内存太多,其他环节可能会因为内存不足产生其他的问题)。
SortShuffleManager和HashShuffleManager
Spark1.2之前使用的ShuffleManager是HashShuffleManager,之后默认使用SortShuffleManager(前面谈到的调优都是和关于HashShuffleManager的),和HashShuffleManager相比,SortShuffleManager比较大的改进就是,之前每个task会根据reduce task的数量来对map的输出分成多个文件,但是在SortShuffleManager中,每个task只输出到一个文件,还会有一个索引文件,reduce只需要根据索引文件来获取自己需要处理的数据。还有,SortShuffleManager会对reduce要处理的数据的值进行排序。
但是,在某些情况下,并不需要开启SortShuffleManager的值进行排序,这种情况下,可以调节spark.shuffle.sort.bypassMergeThreshold参数的值(默认是200),该参数的作用是,当map task创建的输出文件小于等于200时,即reduce task数量少于等于该参数的值时,即使使用SortShuffleManager,在map端,task任务完成时,仍会输出许多文件,但在任务结束后会把这些文件给合并成一个文件。这样做既保留了reduce端拉取多分文件数据时产生的额外开销,还能节省了排序的开销。