第二章 关于MapReduce
Mapreduce中,输入端的数据会被划分成等长的数据块,称之为”分片”,一个map程序处理一个分片。由于每个map程序并行处理一个大文件分割后的文件,可以极大地提高运行速度。
分片大小默认为HDFS的Block块的大小,之所以这么设置的原因是:如果分片的大小比较小,虽然可以提高集群的负载均衡,但是同样也会增加集群管理分片的时间。如果分片的大小比block大,那么task的处理将会跨分片设置跨机架处理,如果出现这种情况,block的数据将会在机器之间发生移动,占用网络资源,同样也会影响数据的处理效率。
map数量的取决于分片的数量,reduce的数量是单独指定的,如果有多个reduce,那么map会对每个输出进行分区,为每个reduce建立一个分区,可以自定义分区函数(即分区器),默认使用的分区器是使用的hash函数进行分区。
map和reduce过程之间有个shuffle过程,如下
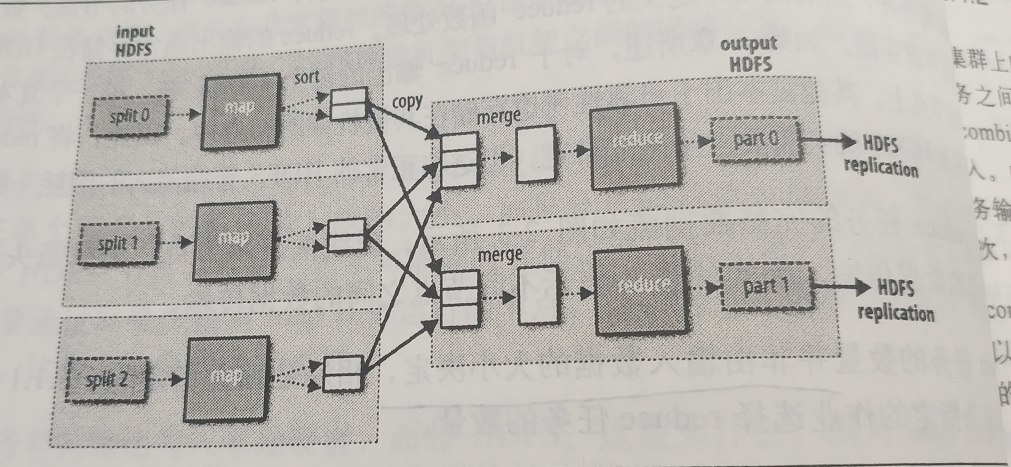
注意:每个map任务的输出会进行分区,分区的数量和reduce的个数一致。
combiner函数
combiner是默认没有开启的一个功能,该功能是属于优化方案,combiner函数的调用是在map进行分区之后,现在本地进行一次小型的reduce过程,然后再进行shuffle,这样可以减少网络IO,比如在进行wordcount计数时,可以现在map分区后,在本地先进行一次汇总,然后再进行shuffle过程,但是对于一些其他的任务,比如求平均值,就不太适用了,因此combiner是否要使用需要根据需求进行斟酌。
第三章 Hadoop分布式文件系统
HDFS上上传的文件初衷是:一次写入,多次读取。HDFS上的文件只支持单个写入者,而且写操作是以“只添加”的方式添加在文件末尾,不支持在文件的任意位置进行修改。
HDFS中文件的存储单位是块(block),hadoop1.x版本中block的大小是64MB,hadoop2.x版本中block的大小是128M,每个块都是独立的,但是与磁盘文件不同的是,HDFS中一个块的大小并不会占据整个块的空间,当存储一个1MB的文件时,只会占据1MB的磁盘空间。
对于经常进行访问的block,datanode会把这些块缓存在堆外缓存中。
HDFS高可用
说到HDFS的高可用,先说下HDFS的镜像文件(fsimage)和编辑日志(edits),镜像文件是HDFS启动时Namenode的一个快照,保存着HDFS的目录结构。编辑日志,顾名思义,就是HDFS启动后,对HDFS目录操作的日志行为,比如删除,增加目录等。在HDFS重启的时候,会对编辑日志进行滚动,然后和镜像文件进行合并。
因此在namenode宕机的情况下,如果要重启另一台机器作为新的namenode需要满意以下几个条件:
1、将镜像文件加载进内存
2、滚动编辑日志
3、接收到足够多的来自datanode的数据块报告
Hadoop2中实现了HDFS的高可用,主要实现方法如下:
配置两个namenode节点,一个主,一个从,两个节点之间共享编辑日志,datanode需要同时向两个namenode发送数据块处理报告。
系统中有一个成为故障转移控制器(failover controller)的实体,管理着主namenode向从namenode转移的过程,原理主要是通过心跳机制监视namenode是否失效。
HDFS读写数据流程
读取数据
1、调用DistributeredFileSystem的一个实例对象的open()方法
2、DistributeredFileSystem通过RPC调用namenode,获取文件起始块的位置,namenode返回每个块的副本datanode位置
3、DistributeredFileSystem返回一个FSDataInputStream对象,该对象进而封装成DFSInputStream对象,该对象管理着datanode和namenode的I/O。
4、之后客户端通过这个存储着datanode地址的DFSInputStream对象,连接最近的datanode,通过反复调用read()方法读取数据,读取完后DFSInputStream关闭和datanode的连接,接着寻找存放下一个文件块的最近datanode
由于namenode只需要响应请求的数据块的位置(这些位置都在内存中,响应很快),再加上数据的副本是分散在不同的datanode上的,这样的设计可以使得集群可以同时接入大量的客户端。
文件写入
文件的写入也是同样需要借助DistributeredFileSystem对象
1、DistributeredFileSystem通过RPC调用create()方法,在namenode中创建一个文件(此时还没有响应的数据块)
2、返回一个FSDataOutputStream对象,FSDataOutputStream封装一个DFSoutPutStream对象,该对象负责处理datanode和namenode之间的通信
3、DFSoutPutStream把要写入的数据分成一个个数据包,放在一个“数据队列”的内部队列中,DataStreamer根据datanode列表挑选出合适的一组datanode来存放数据块(在这个地方,DataStreamer和namenode会进行通信,从而namenode也知道了文件的存储块位置),这些datanode构成一个管线(pipeline),DataStreamer先把一块数据块传输到第一个datanode,然后第一个datanode依次发送给下一个datanode。
4、DFSoutPutStream为每一个发送的数据块维护一个“确认队列”,datanode收到数据后会发送一个确认消息,只有当所有datanode都确认后才会删除。
5、客户端写完后调用close()方法,关闭数据流,告知namenode等待数据复制完成。
如果写入过程datanode出了问题怎么办?
在写入某一份数据出错时,会先关闭原来的管线,把确认队列中的数据包全部放回数据队列,把出错误的datanode数据块打上标记,并将该标记发送给namenode,以便datanode恢复故障后删除错误的数据块。然后把管线中出错误的datanode移除,剩下的datanode构成新的管线,继续发送数据。副本的数量不够由之后namenode察觉后进行复制。