手头数据
用户访问行为数据,字段包括了:date,user_id,session_id,page_id,action_time,search_keyword,click_category_id,click_product_id, order_category_ids,order_product_ids,pay_category_ids,pay_product_ids,city_id
用户数据,字段包括了:
user_id,username,name,age,professional,city,sex
商品信息,字段包括了:
product_id,product_name,extend_info
项目目标
该项目是提供给J2EE平台,使用者通过提交任务,指定年龄,日期,城市等范围内容,对用户的session进行筛选和分析,主要内容包括以下几个方面
1、根据使用者提供的某些条件,对session进行过滤
2、对于筛选过后的session,统计出访问时间在1s~3s、4s~6s、7s~9s、10s~30s、30s~60s、1m~3m、3m~10m、10m~30m、30m以上各个范围内的session占比和访问步长在1~3、4~6、7~9、10~30、30~60、60以上各个范围内的session占比,该步骤的目的是为了了解用户对产品的使用习惯
3、按照时间比例,对session进行随机抽取,目的是为了观察用户的具体点击流/行为。
4、获取点击量、下单量、支付量排名前10的商品种类,该步骤是为了了解符合条件的用户一般都有什么查询或者购买习惯,了解不同条件的用户喜好
5、获取top10的商品种类的点击数量排名前10的session,该步骤是为了了解某些活跃用户群体对最感兴趣的品类的session行为。
各步骤实现
第一步
1、数据方面,项目中是通过随机生成数据模拟真实的应用场景,
在使用者提交任务后,会在数据库中插入一条任务数据,task表结构如下
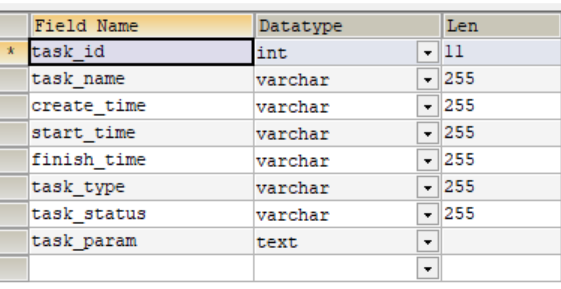
筛选条件是以json格式存放在task_param字段中

筛选主要分为两步,第一步先对时间进行筛选,之后对session聚合后再根据task_param进行过滤
第一步筛选主要代码如下
private static JavaRDD<Row> getActionRDDByDateRange(
SQLContext sqlContext, JSONObject taskParam) {
String startDate = ParamUtils.getParam(taskParam, Constants.PARAM_START_DATE);
String endDate = ParamUtils.getParam(taskParam, Constants.PARAM_END_DATE);
String sql =
"select * "
+ "from user_visit_action "
+ "where date>='" + startDate + "' "
+ "and date<='" + endDate + "'";
DataFrame actionDF = sqlContext.sql(sql);
return actionDF.javaRDD();
}
第二步
2、要计算出各个session的访问时间和步长,首先以session粒度对session数据进行聚合,先把数据转换成
(sessionid,action)的形式(这里的action指的是上面谈到的用户行为数据,因为用户行为数据已经有sessionid字段了,所以只需要简单的map一下即可得到结果)
public static JavaPairRDD<String, Row> getSessionid2ActionRDD(JavaRDD<Row> actionRDD) {
return actionRDD.mapToPair(new PairFunction<Row, String, Row>() {
@Override
public Tuple2<String, Row> call(Row row) throws Exception {
return new Tuple2<String, Row>(row.getString(2), row);
}
});
}
然后,对上面转换后的数据使用groupbykey进行session粒度的聚合,转换成(sessionid,Iterator<Row>)的形式。
对于同一个session来说,最为重要的信息数据就是搜索数据,点击行为,支付行为等,因此这里对(sessionid,Iterator<Row>)形式的数据再次进行聚合,转换成(sessionid,partAggrInfo)的形式,partAggrInfo是一个String类型的字段,以字段名=值的形式和 |
符号进行拼接而成的字符串,为了之后方便把用户的信息也聚合起来,再次数据转换成(userid,partAggrInfo) |
在拼接的时候,会遍历一个session的所有行为数据,因此可以在这一步对该session的访问时间和访问步长进行统计计算。
计算完后,再把转换成的(userid,partAggrInfo)数据和用户数据进行join,把用户的个人信息也添加到partAggrInfo中去,因此整个过程之后的聚合数据形式为(userid,Aggractions)
Aggractions包含的数据有:sessionid,该session的所有搜索词,点击物品的类别,访问时长和访问步长,用户的所有信息,形式如下
String partAggrInfo = Constants.FIELD_SESSION_ID + "=" + sessionid + "|"
+ Constants.FIELD_SEARCH_KEYWORDS + "=" + searchKeywords + "|"
+ Constants.FIELD_CLICK_CATEGORY_IDS + "=" + clickCategoryIds + "|"
+ Constants.FIELD_VISIT_LENGTH + "=" + visitLength + "|"
+ Constants.FIELD_STEP_LENGTH + "=" + stepLength + "|"
+ Constants.FIELD_START_TIME + "=" + DateUtils.formatTime(startTime);
String fullAggrInfo = partAggrInfo + "|"
+ Constants.FIELD_AGE + "=" + age + "|"
+ Constants.FIELD_PROFESSIONAL + "=" + professional + "|"
+ Constants.FIELD_CITY + "=" + city + "|"
+ Constants.FIELD_SEX + "=" + sex;
聚合过程的主要代码如下
private static JavaPairRDD<String, String> aggregateBySession(
SQLContext sqlContext, JavaRDD<Row> actionRDD) {
//先转换成(sessionid,actions)
JavaPairRDD<String, Row> sessionid2ActionRDD = actionRDD.mapToPair(
new PairFunction<Row, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Row> call(Row row) throws Exception {
return new Tuple2<String, Row>(row.getString(2), row);
}
});
// 对行为数据按session粒度进行分组
JavaPairRDD<String, Iterable<Row>> sessionid2ActionsRDD =
sessionid2ActionRDD.groupByKey();
// 对每一个session分组进行聚合,将session中所有的搜索词和点击品类都聚合起来
// 到此为止,获取的数据格式,如下<userid,partAggrInfo(sessionid,searchKeywords,clickCategoryIds)>
JavaPairRDD<Long, String> userid2PartAggrInfoRDD = sessionid2ActionsRDD.mapToPair(
new PairFunction<Tuple2<String, Iterable<Row>>, Long, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, String> call(Tuple2<String, Iterable<Row>> tuple)
throws Exception {
String sessionid = tuple._1;
Iterator<Row> iterator = tuple._2.iterator();
StringBuffer searchKeywordsBuffer = new StringBuffer("");
StringBuffer clickCategoryIdsBuffer = new StringBuffer("");
Long userid = null;
Date startTime = null;
Date endTime = null;
int stepLength = 0;
// 遍历session所有的访问行为
while (iterator.hasNext()) {
// 提取每个访问行为的搜索词字段和点击品类字段
Row row = iterator.next();
if (userid == null) {
userid = row.getLong(1);
}
String searchKeyword = row.getString(5);
Long clickCategoryId = row.getLong(6);
if (StringUtils.isNotEmpty(searchKeyword)) {
if (!searchKeywordsBuffer.toString().contains(searchKeyword)) {
searchKeywordsBuffer.append(searchKeyword + ",");
}
}
if (clickCategoryId != null) {
if (!clickCategoryIdsBuffer.toString().contains(
String.valueOf(clickCategoryId))) {
clickCategoryIdsBuffer.append(clickCategoryId + ",");
}
}
//计算session开始和结束时间
//下面是对该session的访问时间和访问步长进行统计
Date actionTime = DateUtils.parseTime(row.getString(4));
if (startTime == null)
startTime = actionTime;
if (endTime == null)
endTime = actionTime;
if (actionTime.before(startTime)) {
startTime = actionTime;
}
if (actionTime.after(endTime)) {
endTime = actionTime;
}
stepLength++;
}
long visitLength = (endTime.getTime() - startTime.getTime()) / 1000;
String searchKeywords = StringUtils.trimComma(searchKeywordsBuffer.toString());
String clickCategoryIds = StringUtils.trimComma(clickCategoryIdsBuffer.toString());
String partAggrInfo = Constants.FIELD_SESSION_ID + "=" + sessionid + "|"
+ Constants.FIELD_SEARCH_KEYWORDS + "=" + searchKeywords + "|"
+ Constants.FIELD_CLICK_CATEGORY_IDS + "=" + clickCategoryIds + "|"
+ Constants.FIELD_VISIT_LENGTH + "=" + visitLength + "|"
+ Constants.FIELD_STEP_LENGTH + "=" + stepLength + "|"
+ Constants.FIELD_START_TIME + "=" + DateUtils.formatTime(startTime);
return new Tuple2<Long, String>(userid, partAggrInfo);
}
});
// 查询所有用户数据,并映射成<userid,Row>的格式
String sql = "select * from user_info";
JavaRDD<Row> userInfoRDD = sqlContext.sql(sql).javaRDD();
JavaPairRDD<Long, Row> userid2InfoRDD = userInfoRDD.mapToPair(
new PairFunction<Row, Long, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Row> call(Row row) throws Exception {
return new Tuple2<Long, Row>(row.getLong(0), row);
}
});
// 将session粒度聚合数据,与用户信息进行join
JavaPairRDD<Long, Tuple2<String, Row>> userid2FullInfoRDD =
userid2PartAggrInfoRDD.join(userid2InfoRDD);
// 对join起来的数据进行拼接,并且返回<sessionid,fullAggrInfo>格式的数据
JavaPairRDD<String, String> sessionid2FullAggrInfoRDD = userid2FullInfoRDD.mapToPair(
new PairFunction<Tuple2<Long, Tuple2<String, Row>>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(
Tuple2<Long, Tuple2<String, Row>> tuple)
throws Exception {
String partAggrInfo = tuple._2._1;
Row userInfoRow = tuple._2._2;
String sessionid = StringUtils.getFieldFromConcatString(
partAggrInfo, "\\|", Constants.FIELD_SESSION_ID);
int age = userInfoRow.getInt(3);
String professional = userInfoRow.getString(4);
String city = userInfoRow.getString(5);
String sex = userInfoRow.getString(6);
String fullAggrInfo = partAggrInfo + "|"
+ Constants.FIELD_AGE + "=" + age + "|"
+ Constants.FIELD_PROFESSIONAL + "=" + professional + "|"
+ Constants.FIELD_CITY + "=" + city + "|"
+ Constants.FIELD_SEX + "=" + sex;
return new Tuple2<String, String>(sessionid, fullAggrInfo);
}
});
return sessionid2FullAggrInfoRDD;
}
之后对聚合后的数据根据任务参数进行第二次过滤,因为聚合后的数据有用户的个人信息以及session的信息,因此过滤比较简单,除了过滤,在这个过程中还对自定义了一个累加器,对符合条件的session的访问时间和访问步长进行了统计。
自定义累加器的代码如下
public class SessionAggrStatAccumulator implements AccumulatorParam<String> {
// 这两个方法可以理解为一样的。这两个方法,其实主要就是实现,v1可能就是我们初始化的那个连接 v2,就是我们在遍历session的时候,判断出某个session对应的区间,然后会用Constants.TIME_PERIOD_1s_3s 所以,我们,要做的事情就是 在v1中,找到v2对应的value,累加1,然后再更新回连接串里面去
@Override
public String addAccumulator(String v1, String v2) {
return add(v1,v2);
}
@Override
public String addInPlace(String v1, String v2) {
return add(v1,v2);
}
//参数初始化
@Override
public String zero(String initialValue) {
return Constants.SESSION_COUNT + "=0|"
+ Constants.TIME_PERIOD_1s_3s + "=0|"
+ Constants.TIME_PERIOD_4s_6s + "=0|"
+ Constants.TIME_PERIOD_7s_9s + "=0|"
+ Constants.TIME_PERIOD_10s_30s + "=0|"
+ Constants.TIME_PERIOD_30s_60s + "=0|"
+ Constants.TIME_PERIOD_1m_3m + "=0|"
+ Constants.TIME_PERIOD_3m_10m + "=0|"
+ Constants.TIME_PERIOD_10m_30m + "=0|"
+ Constants.TIME_PERIOD_30m + "=0|"
+ Constants.STEP_PERIOD_1_3 + "=0|"
+ Constants.STEP_PERIOD_4_6 + "=0|"
+ Constants.STEP_PERIOD_7_9 + "=0|"
+ Constants.STEP_PERIOD_10_30 + "=0|"
+ Constants.STEP_PERIOD_30_60 + "=0|"
+ Constants.STEP_PERIOD_60 + "=0";
}
/***
* session统计逻辑计算
* @param v1 连接串
* @param v2 范围区间
* @return 更新后的连接串
*/
private String add(String v1,String v2){
if(StringUtils.isEmpty(v1))
return v2;
String oldValue = StringUtils.getFieldFromConcatString(v1,"\\|",v2);
if(oldValue!=null){
int newValue = Integer.valueOf(oldValue)+1;
return StringUtils.setFieldInConcatString(v1,"\\|",v2,String.valueOf(newValue));
}
return v1;
}
}
累加器的使用方法如下,首先创建自定义累加器
Accumulator<String> sessionAggrStatAccumulator = sc.accumulator("",
new SessionAggrStatAccumulator());
之后,在过滤的时候,是需要遍历所有的聚合后数据的,在过滤掉之后,取出原先聚合数据中的访问时间和访问步长数据,进行增加
private static JavaPairRDD<String, String> filterSessionAndAggrStat(
JavaPairRDD<String, String> sessionid2FullAggrInfoRDD,
final JSONObject taskParam,
final Accumulator<String> sessionAggrStatAccumulator) {
JavaPairRDD<String, String> filtersessionid2FullAggrInfoRDD = sessionid2FullAggrInfoRDD.filter(
new Function<Tuple2<String, String>, Boolean>() {
@Override
public Boolean call(Tuple2<String, String> tuple2) throws Exception {
String aggrInfo = tuple2._2;
/**
这里省略过滤代码,过滤过程主要是逐个取出task中的过滤参数,然后依次取出
聚合数据中的相应的字段值,如果不符合条件就返回false
因此到达下面这一行累加器的代码都是通过筛选条件的聚合后的数据
下面这行代码是计算所有通过筛选的数据条数,为了后面计算各个访问时间
和访问步长的数据占比
*/
sessionAggrStatAccumulator.add(Constants.SESSION_COUNT);
//计算访问时长和访问步长
long visitlength = Long.valueOf(StringUtils.getFieldFromConcatString(aggrInfo, "\\|",
Constants.FIELD_VISIT_LENGTH));
long stepLength = Long.valueOf(StringUtils.getFieldFromConcatString(aggrInfo, "\\|",
Constants.FIELD_STEP_LENGTH));
calculateVisitLength(visitlength);
calculateStepLength(stepLength);
return true;
}
private void calculateVisitLength(long visitLength) {
if (visitLength >= 1 && visitLength <= 3)
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_1s_3s);
else if (visitLength >= 4 && visitLength <= 6)
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_4s_6s);
else if (visitLength >= 7 && visitLength <= 9)
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_7s_9s);
else if (visitLength >= 10 && visitLength <= 30)
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_10s_30s);
else if (visitLength >= 30 && visitLength <= 60)
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_30s_60s);
else if (visitLength >= 61 && visitLength <= 180)
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_1m_3m);
else if (visitLength >= 181 && visitLength <= 600)
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_3m_10m);
else if (visitLength >= 601 && visitLength <= 1800)
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_10m_30m);
else if (visitLength > 1800)
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_30m);
}
private void calculateStepLength(long steplength) {
if (steplength >= 1 && steplength <= 3)
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_1_3);
else if (steplength >= 4 && steplength <= 6)
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_4_6);
else if (steplength >= 7 && steplength <= 9)
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_7_9);
else if (steplength >= 10 && steplength <= 30)
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_10_30);
else if (steplength >= 31 && steplength <= 60)
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_30_60);
else if (steplength > 60)
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_60);
}
});
return filtersessionid2FullAggrInfoRDD;
}
第三步
3、随机session抽取中,大致流程如下,首先计算出总的session有多少,然后计算出每个小时都有多少session,按照占比抽出100个(可以修改)随机session
主要过程如下:首先根据filtersessionid2FullAggrInfoRDD计算出Map<yyyy-mm-dd,count>和<yyyy-mm-dd_hour,count>RDD
再把<yyyy-mm-dd_hour,count>RDD转换成Map<yyyy-mm-dd,Map<hour,count>>
遍历这个Map,在结合Map<yyyy-mm-dd,count>即可知道每天中每个小时的占比,然后依次取出即可
第四步
要获取点击量、下单量、支付量排名前10的商品种类,首先先把actionRDD进行过滤,得到符合条件的sessionid2detailRDD ((sessionid,action) action为该session的行为数据。)
然后遍历该RDD,先把点击、下单和支付过程中所有的商品种类id给获取出来,得到categoryidRDD
JavaPairRDD<Long, Long> categoryidRDD = sessionid2detailRDD.flatMapToPair(
new PairFlatMapFunction<Tuple2<String, Row>, Long, Long>() {
@Override
public Iterable<Tuple2<Long, Long>> call(Tuple2<String, Row> tuple2) {
Row row = tuple2._2;
List<Tuple2<Long, Long>> list = new ArrayList<Tuple2<Long, Long>>();
Long clickCategoryId = row.getLong(6);
if (clickCategoryId != null)
list.add(new Tuple2<Long, Long>(clickCategoryId, clickCategoryId));
String orderCategoryIds = row.getString(8);
if (orderCategoryIds != null) {
String[] orderCategoryIdsSplited = orderCategoryIds.split(",");
for (String orderCategoryId : orderCategoryIdsSplited) {
list.add(new Tuple2<Long, Long>(Long.valueOf(orderCategoryId), Long.valueOf(orderCategoryId)));
}
}
String payCategoryIds = row.getString(10);
if (payCategoryIds != null) {
String[] payCategoryIdsSplited = payCategoryIds.split(",");
for (String payCategoryId : payCategoryIdsSplited) {
list.add(new Tuple2<Long, Long>(Long.valueOf(payCategoryId), Long.valueOf(payCategoryId)));
}
}
return list;
}
});
注:遍历后的结果需要distinct进行去重
然后再遍历一次,分别把点击、下单和支付的数量统计出来,下面是统计点击部分的代码,下单和支付的代码与其相似,就不写上去了
先过滤,再map(categoryid,1),最后reducebykey
// 计算各个品类的点击次数
JavaPairRDD<Long, Long> clickCategoryId2CountRDD =
getClickCategoryId2CountRDD(sessionid2detailRDD);
private static JavaPairRDD<Long, Long> getClickCategoryId2CountRDD(
JavaPairRDD<String, Row> sessionid2detailRDD) {
JavaPairRDD<String, Row> clickActionRDD = sessionid2detailRDD.filter(
new Function<Tuple2<String, Row>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<String, Row> tuple) throws Exception {
Row row = tuple._2;
return row.get(6) != null ? true : false;
}
});
JavaPairRDD<Long, Long> clickCategoryIdRDD = clickActionRDD.mapToPair(
new PairFunction<Tuple2<String, Row>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<String, Row> tuple)
throws Exception {
long clickCategoryId = tuple._2.getLong(6);
return new Tuple2<Long, Long>(clickCategoryId, 1L);
}
});
JavaPairRDD<Long, Long> clickCategoryId2CountRDD = clickCategoryIdRDD.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
return clickCategoryId2CountRDD;
}
然后categoryidRDD对clickCategoryId2CountRDD,orderCategoryId2CountRDD,payCategoryId2CountRDD逐个进行左外连接,获取tmpMapRDD,该tmpMapRDD结构如下(Long,String),Long为categoryid,String是把categoryId,点击量,下单量,支付量以 字段名=值的形式拼接而成的字符串,具体看下面代码实现
JavaPairRDD<Long, String> categoryid2countRDD = joinCategoryAndData(
categoryidRDD, clickCategoryId2CountRDD, orderCategoryId2CountRDD,
payCategoryId2CountRDD);
private static JavaPairRDD<Long, String> joinCategoryAndData(
JavaPairRDD<Long, Long> categoryidRDD,
JavaPairRDD<Long, Long> clickCategoryId2CountRDD,
JavaPairRDD<Long, Long> orderCategoryId2CountRDD,
JavaPairRDD<Long, Long> payCategoryId2CountRDD) {
// 解释一下,如果用leftOuterJoin,就可能出现,右边那个RDD中,join过来时,没有值
// 所以Tuple中的第二个值用Optional<Long>类型,就代表,可能有值,可能没有值
JavaPairRDD<Long, Tuple2<Long, Optional<Long>>> tmpJoinRDD =
categoryidRDD.leftOuterJoin(clickCategoryId2CountRDD);
JavaPairRDD<Long, String> tmpMapRDD = tmpJoinRDD.mapToPair(
new PairFunction<Tuple2<Long, Tuple2<Long, Optional<Long>>>, Long, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, String> call(
Tuple2<Long, Tuple2<Long, Optional<Long>>> tuple)
throws Exception {
long categoryid = tuple._1;
Optional<Long> optional = tuple._2._2;
long clickCount = 0L;
if (optional.isPresent()) {
clickCount = optional.get();
}
String value = Constants.FIELD_CATEGORY_ID + "=" + categoryid + "|" +
Constants.FIELD_CLICK_COUNT + "=" + clickCount;
return new Tuple2<Long, String>(categoryid, value);
}
});
tmpMapRDD = tmpMapRDD.leftOuterJoin(orderCategoryId2CountRDD).mapToPair(
new PairFunction<Tuple2<Long, Tuple2<String, Optional<Long>>>, Long, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, String> call(
Tuple2<Long, Tuple2<String, Optional<Long>>> tuple)
throws Exception {
long categoryid = tuple._1;
String value = tuple._2._1;
Optional<Long> optional = tuple._2._2;
long orderCount = 0L;
if (optional.isPresent()) {
orderCount = optional.get();
}
value = value + "|" + Constants.FIELD_ORDER_COUNT + "=" + orderCount;
return new Tuple2<Long, String>(categoryid, value);
}
});
tmpMapRDD = tmpMapRDD.leftOuterJoin(payCategoryId2CountRDD).mapToPair(
new PairFunction<Tuple2<Long, Tuple2<String, Optional<Long>>>, Long, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, String> call(
Tuple2<Long, Tuple2<String, Optional<Long>>> tuple)
throws Exception {
long categoryid = tuple._1;
String value = tuple._2._1;
Optional<Long> optional = tuple._2._2;
long payCount = 0L;
if (optional.isPresent()) {
payCount = optional.get();
}
value = value + "|" + Constants.FIELD_PAY_COUNT + "=" + payCount;
return new Tuple2<Long, String>(categoryid, value);
}
});
return tmpMapRDD;
}
最后的排序过程,这里我们采用自定义比较器来进行排序,自定义比较器代码如下
public class CategorySortKey implements Ordered<CategorySortKey>, Serializable{
private long clickCount;
private long orderCount;
private long payCount;
public CategorySortKey(long clickCount, long orderCount, long payCount) {
this.clickCount = clickCount;
this.orderCount = orderCount;
this.payCount = payCount;
}
@Override
public boolean $greater(CategorySortKey other) {
if(clickCount > other.getClickCount()) {
return true;
} else if(clickCount == other.getClickCount() &&
orderCount > other.getOrderCount()) {
return true;
} else if(clickCount == other.getClickCount() &&
orderCount == other.getOrderCount() &&
payCount > other.getPayCount()) {
return true;
}
return false;
}
@Override
public boolean $greater$eq(CategorySortKey other) {
if($greater(other)) {
return true;
} else if(clickCount == other.getClickCount() &&
orderCount == other.getOrderCount() &&
payCount == other.getPayCount()) {
return true;
}
return false;
}
@Override
public boolean $less(CategorySortKey other) {
if(clickCount < other.getClickCount()) {
return true;
} else if(clickCount == other.getClickCount() &&
orderCount < other.getOrderCount()) {
return true;
} else if(clickCount == other.getClickCount() &&
orderCount == other.getOrderCount() &&
payCount < other.getPayCount()) {
return true;
}
return false;
}
@Override
public boolean $less$eq(CategorySortKey other) {
if($less(other)) {
return true;
} else if(clickCount == other.getClickCount() &&
orderCount == other.getOrderCount() &&
payCount == other.getPayCount()) {
return true;
}
return false;
}
@Override
public int compare(CategorySortKey other) {
if(clickCount - other.getClickCount() != 0) {
return (int) (clickCount - other.getClickCount());
} else if(orderCount - other.getOrderCount() != 0) {
return (int) (orderCount - other.getOrderCount());
} else if(payCount - other.getPayCount() != 0) {
return (int) (payCount - other.getPayCount());
}
return 0;
}
@Override
public int compareTo(CategorySortKey other) {
return compare(other);
}
public long getClickCount() {
return clickCount;
}
public void setClickCount(long clickCount) {
this.clickCount = clickCount;
}
public long getOrderCount() {
return orderCount;
}
public void setOrderCount(long orderCount) {
this.orderCount = orderCount;
}
public long getPayCount() {
return payCount;
}
public void setPayCount(long payCount) {
this.payCount = payCount;
}
}
比较的代码如下,依次取出每个category的点击数,下单数和支付数,创建CategorySortKey对象作为键,依然把存放有categoryid,点击数,下单数,支付数的String作为值,然后sortByKey即可。
JavaPairRDD<CategorySortKey, String> sortKey2countRDD = categoryid2countRDD.mapToPair(
new PairFunction<Tuple2<Long, String>, CategorySortKey, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<CategorySortKey, String> call(
Tuple2<Long, String> tuple) throws Exception {
String countInfo = tuple._2;
long clickCount = Long.valueOf(StringUtils.getFieldFromConcatString(
countInfo, "\\|", Constants.FIELD_CLICK_COUNT));
long orderCount = Long.valueOf(StringUtils.getFieldFromConcatString(
countInfo, "\\|", Constants.FIELD_ORDER_COUNT));
long payCount = Long.valueOf(StringUtils.getFieldFromConcatString(
countInfo, "\\|", Constants.FIELD_PAY_COUNT));
CategorySortKey sortKey = new CategorySortKey(clickCount, orderCount, payCount);
return new Tuple2<CategorySortKey, String>(sortKey, countInfo);
}
});
JavaPairRDD<CategorySortKey, String> sortedCategoryCountRDD =
sortKey2countRDD.sortByKey(false);
最后使用take(10)获取即可
第五步
首先获取第四步中top10的商品种类信息top10CategoryList
对sessionid2detailsRDD使用flatMap算子计算出所有session点击商品类别的次数,转换成<categoryid,info>,info是以sessionid+点击数为值的字符串,把top10CategoryList转换成top10CategoryIdRDD,和刚才的结果进行join操作,再maptopair,即可得到top10的<categoryid,info>
然后对<categoryid,info>进行抽取操作即可获取top10category的活跃session
private static void getTop10Session(
JavaSparkContext sc,
final long taskid,
List<Tuple2<CategorySortKey, String>> top10CategoryList,
JavaPairRDD<String, Row> sessionid2detailRDD) {
//第一步:将top10热门品类id,生成一份RDD
List<Tuple2<Long, Long>> top10CategoryIdList = new ArrayList<Tuple2<Long, Long>>();
for(Tuple2<CategorySortKey, String> category : top10CategoryList) {
long categoryid = Long.valueOf(StringUtils.getFieldFromConcatString(
category._2, "\\|", Constants.FIELD_CATEGORY_ID));
top10CategoryIdList.add(new Tuple2<Long, Long>(categoryid, categoryid));
}
JavaPairRDD<Long, Long> top10CategoryIdRDD = sc.parallelizePairs(top10CategoryIdList);
JavaPairRDD<String, Iterable<Row>> sessionid2detailsRDD =
sessionid2detailRDD.groupByKey();
//第二步:计算top10品类被各session点击的次数
JavaPairRDD<Long, String> categoryid2sessionCountRDD = sessionid2detailsRDD.flatMapToPair(
new PairFlatMapFunction<Tuple2<String, Iterable<Row>>, Long, String>() {
@Override
public Iterable<Tuple2<Long, String>> call(Tuple2<String, Iterable<Row>> tuple) throws Exception {
String sessionid = tuple._1;
Iterator<Row> iterator = tuple._2.iterator();
Map<Long, Long> categoryCountMap = new HashMap<Long, Long>();
while (iterator.hasNext()) {
Row row = iterator.next();
if (row.get(6) != null) {
long categoryid = row.getLong(6);
Long count = categoryCountMap.get(categoryid);
if (count == null) {
count = 0L;
}
count++;
categoryCountMap.put(categoryid, count);
}
}
// 返回结果,<categoryid,session+","+count>的格式
List<Tuple2<Long, String>> list = new ArrayList<Tuple2<Long, String>>();
for (Map.Entry<Long, Long> categoryCountEntry : categoryCountMap.entrySet()) {
long categoryid = categoryCountEntry.getKey();
long count = categoryCountEntry.getValue();
String value = sessionid + "," + count;
list.add(new Tuple2<Long, String>(categoryid, value));
}
return list;
}
});
JavaPairRDD<Long,String> top10CategorySessionCountRDD =
top10CategoryIdRDD.join(categoryid2sessionCountRDD)
.mapToPair(new PairFunction<Tuple2<Long, Tuple2<Long, String>>, Long, String>() {
@Override
public Tuple2<Long, String> call(Tuple2<Long, Tuple2<Long, String>> tuple) throws Exception {
return new Tuple2<Long, String>(tuple._1,tuple._2._2);
}
});
}