Hive是将HQL语句转换成MR程序,简化了程序的编写,SparkSQL能转换成RDD,同样是简化程序的开发。
SparkSQL提供了两个新的数据抽象,分别是DataFrame(Spark1.3)和DataSet(Spark1.6)
DataFrame
DataFrame与RDD相比,DataFrame更想是一张数据库表,除了知道表中数据以外,还能知道数据的结构信息
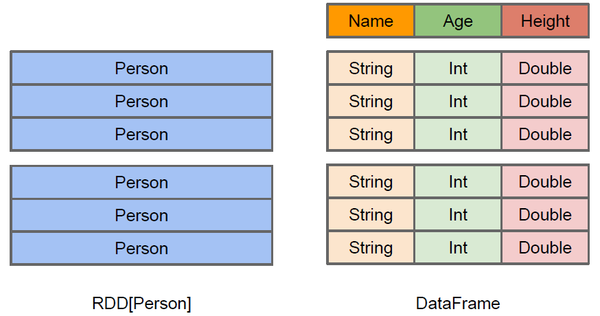
从上图可以明显地看出RDD和DataFrame的区别,RDD只知道存储的是person类型,里面的数据结构对于RDD来言相当于一个黑盒,如果想对RDD进行一些操作,比如逐行去查看,比如想要查询出年龄在某个范围之内的数据,RDD必须每一行都去遍历,然后取出年龄那一列然后进行判断,如果想要进行一些聚合操作则更为复杂。DataFrame知道存储内容的详细信息。DataFrame除了提供能丰富的算子以外,还提供了更多的性能优化,比如filter下推,裁剪等。
此外,DataFrame还提供了Schema的视图,可以把DataFrame当做一张表来使用。
DataFrame的性能比较高主要是下面两个原因:
1、定制化内存管理:数据是存放在非堆内存,摆脱了GC的限制
2、优化的执行计划:查询计划通过 Spark catalyst optimiser 进行优化
创建DataFrame的三种方式:
1、从已经存在的RDD进行转换
val peopleRDD = sc.textFile("C:\\Users\\KiloMeter\\Desktop\\各种文档什么玩意\\spark\\person.txt")
import spark.implicits._
val peopleDF = peopleRDD.map(_.split(" ")).map(
paras => (paras(0).trim,paras(1).toInt)).toDF("name","age")
peopleDF.show()
可以看到,创建时需要指定列名,如果DataFrame中的数据是case类的话,会自动将类的字段名映射成表名
因为指定case类后,参数的类型也已经确定了,因此下面这段代码最后也能转换成DataSet
val peopleDF = sc.textFile("C:\\Users\\KiloMeter\\Desktop\\各种文档什么玩意\\spark\\person.txt")
.map(_.split(" ")).map(
parmas => Person(parmas(0).trim,parmas(1).toLong)).toDF()
peopleDF.select("name").show()
2、从HiveTable进行查询返回
3、通过Spark的数据源创建
var df = spark.read.json("C:\\Users\\KiloMeter\\Desktop\\各种文档什么玩意\\spark\\person.json")
上面讲到,DataFrame可以当做一张数据库表来使用,使用的方式有两种,第一种是DSL风格语法,第二种是熟悉的SQL语法
**DSL 风格语法 **
peopleDF.select("name").show()
peopleDF.select($"name", $"age" + 1).show()
peopleDF.filter($"age" > 21).show()
peopleDF.groupBy("age").count().show()
SQL风格语法
peopleDF.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
DataSet
DateFrame的缺点就是缺少类型检查,可能会因为类型问题在运行时出错。DataSet是DataFram API的扩展,具有了类型检查,Dataframe可以说是是Dataset的特例,DataFrame=Dataset[Row] ,所以可以通过 as 方法将 Dataframe 转换为 Dataset
创建DataSet的方法
由于DataSet是强类型的,需要在创建的时候就指定字段的类型
val personDS = Seq(Person("km",10)).toDS()
personDS.show()
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect().foreach(println)
val path = "C:\\Users\\KiloMeter\\Desktop\\各种文档什么玩意\\spark\\person.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
DataFrame、DataSet和RDD相互转换
DataFrame、DataSet转换成RDD比较简单
val rdd1 = testDF.rdd
val rdd2 = testDS.rdd
DataSet转换成DataFrame
import spark.implicits._
val testDF = testDS.toDS()
RDD转换成DataFrame
val peopleDF = sc.textFile("C:\\Users\\KiloMeter\\Desktop\\各种文档什么玩意\\spark\\person.txt")
.map(_.split(" ")).map(
parmas => (parmas(0).trim,parmas(1).toLong)).toDF()
RDD转换成DataSet
case class Person(name: String, age: Long) extends Serializable
val peopleDF = sc.textFile("C:\\Users\\KiloMeter\\Desktop\\各种文档什么玩意\\spark\\person.txt")
.map(_.split(" ")).map(
parmas => Person(parmas(0).trim,parmas(1).toLong)).toDF()
DataFrame转换成DataSet
import spark.implicits._
val peopleDF = sc.textFile("C:\\Users\\KiloMeter\\Desktop\\各种文档什么玩意\\spark\\person.txt")
.map(_.split(" ")).map(parmas => (parmas(0).trim,parmas(1).toLong)).toDF("name","age")
val peopleDS = peopleDF.as[Person]
SparkSession读取和存储文件
Spark SQL 的默认数据源为 Parquet 格式。数据源为 Parquet 文件时, SparkSQL 可以方便的执行所有的操作。当读取的文件格式不是Parquet 时,需要指定文件的读取格式,如json,csv等
val peopleDF = spark.read.format("json").load("C:\\Users\\KiloMeter\\Desktop\\各种文档什么玩意\\spark\\person.json")
同样保存的时候,需要指定保存的格式
peopleDF.write.format("csv").save("C:\\Users\\KiloMeter\\Desktop\\各种文档什么玩意\\spark\\person.csv")