什么是RDD
RDD(Resilient Distributed Dataset ) 弹性分布式数据集,是Spark中最基本的数据抽象,Spark中对数据的所有操作都是建立在RDD上的,不外乎创建RDD,转换已有RDD以及调用RDD操作求值,每个RDD都被分为多个分区,这些分区运行在集群的不同节点上,RDD具有流式模型的特点:自动容错、位置感知性调度和可伸缩性。
RDD的基本概念
1. Application
用户在spark上构建的程序,包含了driver程序以及集群上的executors
2. Driver
主要完成任务的调度以及和executor和cluster manager进行协调。
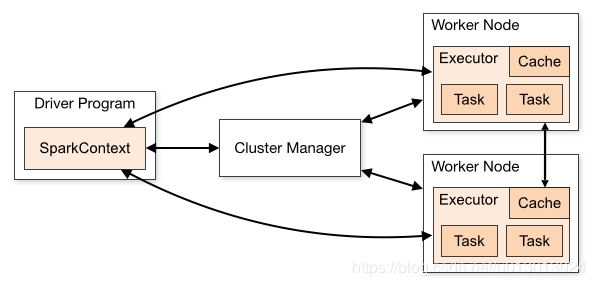
3. Cluster Manager
集群的资源管理器,在集群上获取资源的外部服务,比如Yarn
客户端程序会向yarn申请计算任务需要多大内存,多少CPU,然后Cluster Manager会通过调度告诉客户端可以使用,然后客户端就把程序送到每个Worker node上执行了
4.Worker Node
集群中任何一个可以运行spark应用代码的节点。
Worker Node就是物理节点,可以在上面启动Executor进程,执行多个task。
5.Executor
在每个WorkerNode上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor,一个节点可以启动多个executor,每个executor上可以启动多个core线程来处理task,一个core线程处理一个task,每个Task执行的结果就是生成了目标RDD的一个partition。
Executor是一个执行Task的容器。它的主要职责是:
1、初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。
2、同时还有一个ExecutorBackend向cluster manager汇报当前的任务状态,这一方面有点类似hadoop的tasktracker和task。
6.Job
Spark中的一个action算子就会触发一个job,Job会提交给DAGScheduler,根据shuffle分解成Stage
7. Task
Task是Spark中最新的执行单元。RDD在物理上是被分成多个partitions的,每个并行的Task执行的任务全都是相同的,区别就是在于执行在不同的partition上。
8. 依赖关系
Spark中RDD的粗粒度操作,每一次transformation都会生成一个新的RDD,这样就会建立RDD之间的前后依赖关系,在Spark中,依赖关系被定义为两种类型,分别是窄依赖和宽依赖
- 窄依赖,父RDD的分区最多只会被子RDD的一个分区使用,
- 宽依赖,父RDD的一个分区会被子RDD的多个分区使用
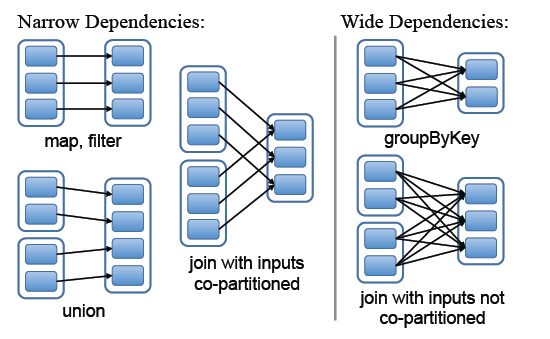
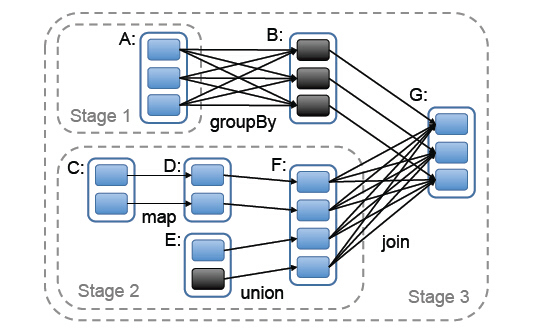
9. Stage
stage的划分是Spark作业调度的关键一步,它基于DAG确定依赖关系,借此来划分stage,将依赖链断开,每个stage内部可以并行运行,整个作业按照stage顺序依次执行,最终完成整个Job。Stage的划分和上一点的依赖关系有关系,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到宽依赖就断开,遇到窄依赖就将其加入到当前stage。stage中task数目由stage末端的RDD分区个数来决定,RDD转换是基于分区的一种粗粒度计算,一个stage执行的结果就是这几个分区构成的RDD。
RDD属性
1、一组分片(partition),是数据集的基本组成单位,在RDD中,每个分片会被一个计算任务处理,并决定计算的粒度,用户可以在创建RDD的时候指定分片数量,默认是程序分配到的CPU Core数目
2、RDD之间存在依赖关系,RDD的每次转换都会生成新的RDD,当某个分区的RDD在计算过程发生数据丢失时,程序会根据这个依赖关系重新计算丢失的分区数据,而不是全部分区重新计算。
3、RDD的partition是partitioner(分片函数)决定的,目前Spark的分片函数有HashPartitioner(哈希分区)和RangePartitioner(范围分区)。只有K-V(键值对)的RDD才有partitioner,其他RDD的partitioner为None,partitioner不仅决定了分片数量,还决定了shuffle后输出的分片数量
RDD的弹性
弹性分布式数据集,弹性的意思指的是:
1、RDD的数据会自动在内存和磁盘中切换,Spark会优先把数据放在内存,如果放不下,程序会自动切换。
2、基于血统的容错机制,如上面RDD属性第二点,RDD的转换会形成依赖链,当某个RDD失效时,可以通过依赖链重新计算获取。
3、Task如果失败会自动进行重试,默认次数是4次。
4、Job的某个Stage如果失败也会自动进行重试,默认次数也是4次。
5、cache,persist和checkpoint:RDD在计算过程中,当遇到某个节点宕掉的话,需要根据依赖链重新计算,如果计算量太大的话,会影响整个程序的运行,此外,如果某个中间RDD会被反复调用,默认是会从头开始调用RDD的,此时可以使用cache将这个中间RDD缓存到内存当中,cache方法底层调用的就是persist,区别就是cache只会把结果缓存到JVM堆内存中,而persist有多种缓存方式,可以部分缓存到内存,部分缓存到硬盘。而checkpoint则是把数据持久化到HDFS上,这样是因为,如果依赖链太长,重新计算的代价也很大,而且在内存中也有可能会丢失,如果持久化到HDFS上,之后可以直接在HDFS上取即可。此外,存储到HDFS上后,该RDD的所有父依赖都会被移除。
checkpoint和persist的区别:
checkpoint是把数据持久化到HDFS上的,是由数据备份的,即使挂掉一个,仍然能够其他节点上获取,而persist是把数据缓存到本地硬盘,如果executor宕掉了,上面cache的RDD就会丢失,数据得根据依赖链重新计算。
6、数据调度弹性:Spark将整个计算过程抽象成通用的有向无环图DAG,可以将多Stage的任务串联或并联执行,调度引擎自动处理Stage的失败和task的失败
Spark概念总结
由于Spark中的概念很多,比如partition,task,job等等,这里把所有关系捋一捋。
spark在执行每个application时,会启动Driver和executor两种JVM进程,Driver为主控进程,负责执行application的main方法,Driver是master机器上新建的JVM进程,master负责资源的调度分配,因此Driver会向master索要资源,会在worker上申请executor进程。
executor负责执行Task,并将结果返回给Driver。
在application中,Spark将RDD分成多个partition,一个partition的整个运算过程称之为一个task,RDD转换过程中,一个action操作就划分出一个Job,以shuffle操作为边界划分Stage,同一个Stage中的所有task可以并行运算。
RDD的计算过程中,一个分区会起一个task,因此rdd的分区数决定了task的数量。
executor的数量和每个executor上的核数决定了同一时间可以启动多少个task。
如果你的rdd有100个分区,10个executor,每个executor有2个核,那么一次可以执行20个task,全部计算完需要5个轮次,如果有101个分区,那么需要执行6个轮次,最后一次只有一个task在运行,其他核都在空转。如果资源不变,但是rdd只有2个分区,那么每次只能有2个task运行,其余18个核都在空转。因此在spark调优时,可以采取增加分区的数目来提高task的并行度。