环境搭建
1、解压HBase安装包

2、修改配置文件
修改conf/hbase-env.sh
#设置jdk路径
export JAVA_HOME=/usr/local/software/jdk1.8.0_191
# 关闭hbase自带的zookeeper
export HBASE_MANAGES_ZK=false
修改conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<!-- 这里指定hdfs端口-->
<value>hdfs://niubike1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<!--如果要配置HMaster高可用 这里只需要写端口号即可-->
<value>niubike1:60000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>niubike1,niubike2,niubike3</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/software/hbase-0.98.6-cdh5.3.6/dataDir</value>
</property>
</configuration>
修改conf/regionservers
niubike1
niubike2
niubike3
3、修改lib下面关于hadoop和zookeeper有关jar包
这里我用的hadoop版本和hbase/lib下面的hadoop包版本刚好一致,因此我这里无需替换,如果不一致(可以进去hbase/lib下面查看以hadoop开头的jar包,有显示其版本号),需要一个一个删除掉,并从你自己安装的hadoop中,把hadoop里面原有的包拷贝到hbase里面。
zookeeper同理也是,我这里的使用zookeeper版本和其版本不一致,因此得进行替换。

ZK需要的替换的jar包只有一个,但是hadoop需要替换的jar包比较多,如下
hadoop-annotations-2.5.0.jar
hadoop-auth-2.5.0-cdh5.3.6.jar
hadoop-client-2.5.0-cdh5.3.6.jar
hadoop-common-2.5.0-cdh5.3.6.jar
hadoop-hdfs-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-app-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-common-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-core-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-hs-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-hs-plugins-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-jobclient-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-jobclient-2.5.0-cdh5.3.6-tests.jar
hadoop-mapreduce-client-shuffle-2.5.0-cdh5.3.6.jar
hadoop-yarn-api-2.5.0-cdh5.3.6.jar
hadoop-yarn-applications-distributedshell-2.5.0-cdh5.3.6.jar
hadoop-yarn-applications-unmanaged-am-launcher-2.5.0-cdh5.3.6.jar
hadoop-yarn-client-2.5.0-cdh5.3.6.jar
hadoop-yarn-common-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-applicationhistoryservice-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-common-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-nodemanager-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-resourcemanager-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-tests-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-web-proxy-2.5.0-cdh5.3.6.jar
zookeeper-3.4.5-cdh5.3.6.jar
4、分发安装包
上述配置完后,将hbase安装包全部分到其他机器上
scp -r /usr/local/software/hbase-0.98.6-cdh5.3.6 niubike2:/usr/local/software
scp -r /usr/local/software/hbase-0.98.6-cdh5.3.6 niubike3:/usr/local/software
5、将Hadoop配置文件软连接到HBase的conf目录下
core-site.xml
$ ln -s /usr/local/software/hadoop-2.5.0-cdh5.3.6/etc/hadoop/core-site.xml /usr/local/software/hbase-0.98.6-cdh5.3.6/conf/core-site.xml
hdfs-site.xml
$ ln -s /usr/local/software/hadoop-2.5.0-cdh5.3.6/etc/hadoop/hdfs-site.xml /usr/local/software/hbase-0.98.6-cdh5.3.6/conf/hdfs-site.xml
其他几台机器也要做此操作
直接拷贝过去也可以。
6、启动hbase
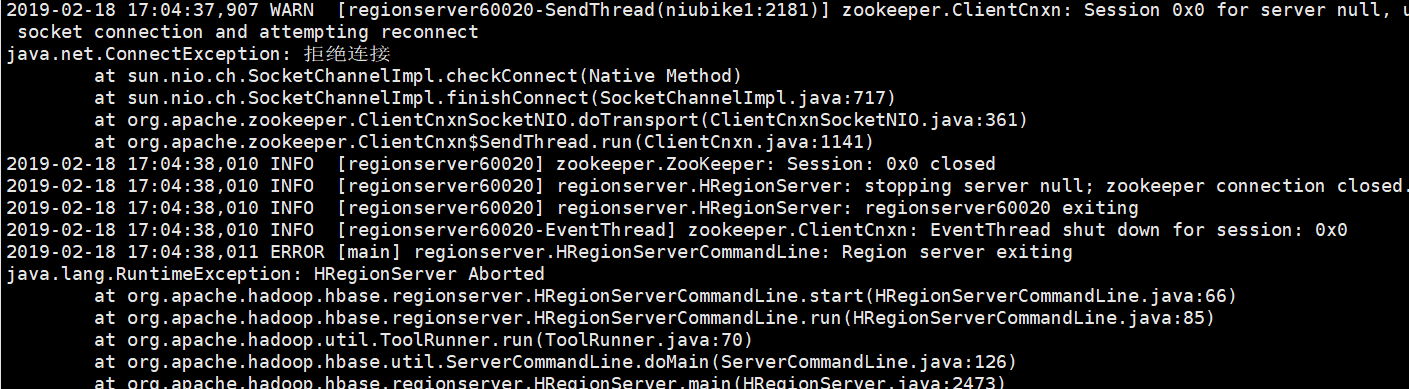
启动前必须先启动hdfs,zookeeper,不然会连接报错,启动失败
# 这两条指令需要在各自的机器上执行
$ bin/hbase-daemon.sh start master
$ bin/hbase-daemon.sh start regionserver
# 这条指令为群起指令
$ bin/start-hbase.sh
# 对应的停止命令:
$ bin/stop-hbase.sh
输入启动命令之后可以使用jps查看。如果没有启动成功得去查看下log日志,日志位置在log文件夹里面。
启动后可以通过WEB界面端查看 默认端口是60010
这里我在启动后发现三台机器上的HRegionServer都有启动,但是HMaster没有启动,查看了日志发现是前面一个配置文件hdfs端口写错了。
后面在成功启动后,访问连接上了但是界面一直无法显示,查看日志问题如下

从Stack Overflow上找了下,问题可能有以下几个方面
1、只有NameNode实例正在运行且它不处于安全模式
2、没有DataNode实例启动并运行,或者有些实例已经死亡。 (检查服务器)
3、Namenode和Datanode实例都在运行,但它们无法相互通信,这意味着DataNode和NameNode实例之间存在连接问题。
4、由于基于hadoop的问题的某些网络,运行DataNode实例无法与服务器通信(检查包含datanode信息的日志) 5、在DataNode实例的已配置数据目录中没有指定硬盘空间,或者DataNode实例的空间不足。 (检查dfs.data.dir //删除旧文件,如果有的话) 5、dfs.datanode.du.reserved中为DataNode实例指定的保留空间超过了使DataNode实例理解没有足够可用空间的可用空间。 6、DataNode实例没有足够的线程(检查datanode日志和dfs.datanode.handler.count值)
7、确保dfs.data.transfer.protection不等于“authentication”,dfs.encrypt.data.transfer等于true。
我一开始以为是hadoop出了问题,把hadoop给初始化了(一般没事不要初始化,初始化后啥东西都没了),发现初始化后启动hadoop,datanode启动不了。查看日志错误如下

原因是初始化后,主节点的namenode clusterID与从节点的datanode clusterID不一致
多次格式化了namenode跟datanode之后的结果,格式化之后从节点生成了新的ID,造成不一致
因此需要修改下clusterID,保持namenode和datanode的clusterID保持一致。
后来发现格式化后问题并没有得到解决。
然后我怀疑可能是磁盘空间不够(之前曾出现过namenode上磁盘空间满了的情况),查看了下datanode的磁盘情况
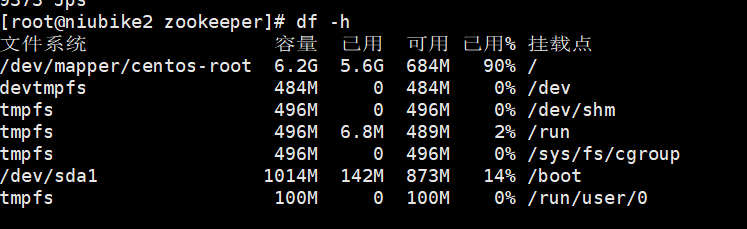
发现两台datanode的硬盘空间都使用了90+,然后用
du -sh *
查看下哪些文件占用了较大的空间,清理后重启hadoop和hbase就成功了。
HBase基本操作
启动HBase客户端
bin/hbase shell
查看帮助命令
hbase(main):001:0> help
查看当前数据库中有哪些表
hbase(main):002:0> list
创建一张表
# student是表名,info是列族名
hbase(main):003:0> create 'student','info'
添加数据
# 表名 ROWKEY 列族名:列名 值
hbase(main):004:0> put 'student','1001','info:name','Thomas'
hbase(main):005:0> put 'student','1001','info:sex','male'
hbase(main):006:0> put 'student','1001','info:age','18'
扫描表中存储的数据
hbase(main):007:0> scan 'student'

查看某个rowkey范围内的数据
#扫描rowkey范围在1001-1002的数据
hbase(main):014:0> scan 'student',{STARTROW => '1001',STOPROW => '1002'}
查看表结构
hbase(main):009:0> describe 'student'
更新字段值
hbase(main):009:0> put 'student','1001','info:name','Nick'
hbase(main):010:0> put 'student','1001','info:age','100'
查看指定行的数据
hbase(main):012:0> get 'student','1001'
查看指定行指定列或列族的数据
hbase(main):013:0> get 'student','1001','info:name'
删除某一个rowkey全部的数据
hbase(main):015:0> deleteall 'student','1001'
删除某个rowkey中某一列的数据
hbase(main):016:0> delete 'student','1001','info:sex'
清空表数据
hbase(main):017:0> truncate 'student'
删除表
首先需要先让该表为disable状态
hbase(main):018:0> disable 'student'
然后才能drop这个表
hbase(main):019:0> drop 'student'
如果直接drop表,会报错:Drop the named table. Table must first be disabled)
统计一张表有多少行数据
hbase(main):020:0> count 'student'