因为hadoop是用Java开发的,所以先确保自己集群的所有机器都已经成功安装好了JDK。
在master主机上把hadoop包解压。
修改配置文件
hadoop解压包下的etc/hadoop/hadoop-nev.sh
1、修改/{hadoop解压路径}/etc/hadoop/hadoop-nev.sh 添加JAVA_HOME

2、修改/{hadoop解压路径}/etc/hadoop/core-site.xml
添加以下属性
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://niubike1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/software/hadoop-2.5.0-cdh5.3.6/data</value>
</property>
</configuration>
特别注意:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删除,必须重新执行format才行,否则会出错。
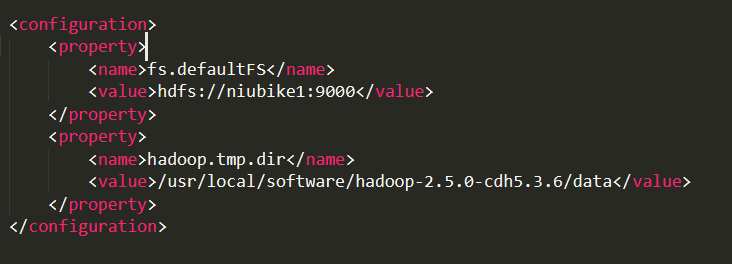
3、修改/{hadoop解压路径}/etc/hadoop/hdfs-site.xml
<configuration>
<!--指定hdfs数据的冗余份数 默认是3-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/software/hadoop-2.5.0-cdh5.3.6/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/software/hadoop-2.5.0-cdh5.3.6/hdfs/data</value>
</property>
</configuration>
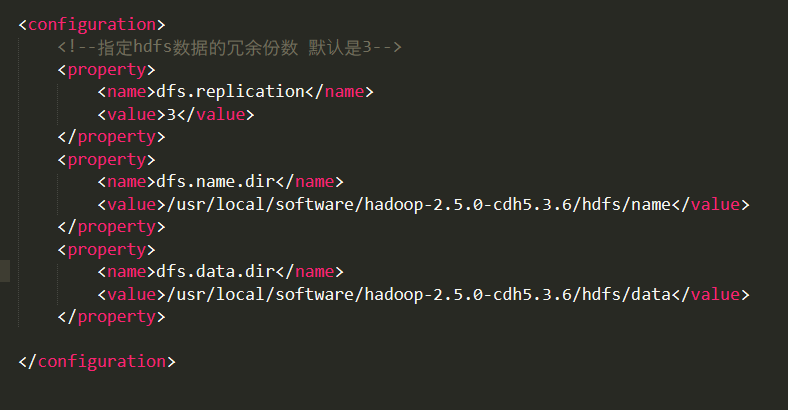
4、修改/{hadoop解压路径}/etc/hadoop/mapred-site.xml
刚解压后里面是没有mapred-site.xml这个文件的,只有mapred-site.xml.template文件,该文件是mapred-site.xml的模板,直接拷贝一份该文件改名为mapred-site.xml,然后在上面修改即可。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://niubike1:9001</value>
</property>
</configuration>
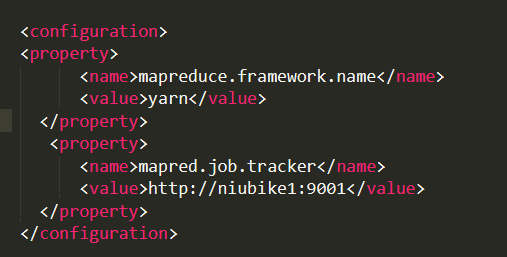
5、修改/{hadoop解压路径}/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>niubike1</value>
</property>
</configuration>
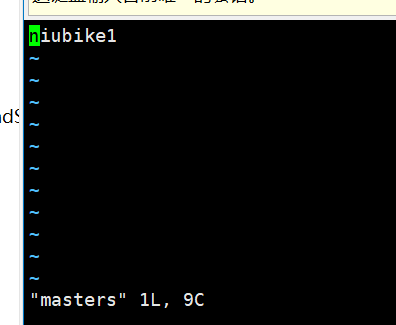
6、新增masters文件
在masters文件中写入master的IP。
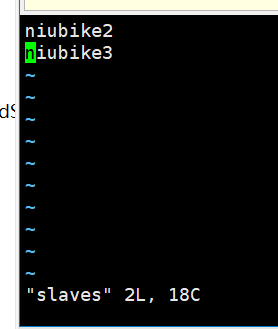
7、修改slavers文件内容(该文件为master主机仅有,其他机器不用这个文件)
添加各个slavers节点的IP
8、在master上把上述内容修改完毕后,在master上把整个hadoop文件夹复制到其他slavers机器上
scp -r /usr/local/software/hadoop-2.5.0-cdh5.3.6 niubike1:/usr/local/software
9、删除slavers上刚复制过去的hadoop文件夹上的slavers文件
rm -rf /usr/local/software/hadoop-2.5.0-cdh5.3.6/etc/hadoop/slaves
10、配置环境变量
vim /etc/profile
## 内容
export HADOOP_HOME=/usr/local/software/hadoop-2.5.0-cdh5.3.6
export PATH=$PATH:$HADOOP_HOME/bin
## 使配置文件生效
source /etc/profile
启动集群
1、格式化HDFS文件系统
进入master的~/hadoop目录,执行以下操作
bin/hadoop namenode -format
格式化namenode,第一次启动服务前执行的操作,以后不需要执行。
2、然后启动hadoop:
sbin/start-all.sh
3、使用jps命令查看运行情况
#master 执行 jps查看运行情况
25928 SecondaryNameNode
25742 NameNode
26387 Jps
26078 ResourceManager
#slave 执行 jps查看运行情况
24002 NodeManager
23899 DataNode
24179 Jps
4、命令查看Hadoop集群的状态
通过简单的jps命令虽然可以查看HDFS文件管理系统、MapReduce服务是否启动成功,但是无法查看到Hadoop整个集群的运行状态。我们可以通过hadoop dfsadmin -report进行查看。用该命令可以快速定位出哪些节点挂掉了,HDFS的容量以及使用了多少,以及每个节点的硬盘使用情况。
hadoop dfsadmin -report
输出结果:
Configured Capacity: 50108030976 (46.67 GB)
Present Capacity: 41877471232 (39.00 GB)
DFS Remaining: 41877385216 (39.00 GB)
DFS Used: 86016 (84 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
......
5、hadoop 重启
sbin/stop-all.sh
sbin/start-all.sh
错误
在搭建完成启动的时候,发生过两个错误:
1、 xxx: Error: JAVA_HOME is not set and could not be found
这个错误意思没有找到jdk的环境变量,需要在hadoop-env.sh配置。
vim /usr/local/software/hadoop-2.5.0-cdh5.3.6/etc/hadoop/hadoop-env.sh
## 配置项
export JAVA_HOME=/usr/local/software/jdk1.8.0_191
2、The authenticity of host ‘0.0.0.0 (0.0.0.0)’ can’t be established.
解决方案关闭SELINUX
-- 关闭SELINUX
# vim /etc/selinux/config
-- 注释掉
#SELINUX=enforcing
#SELINUXTYPE=targeted
— 添加
SELINUX=disabled