基本概念
字母表
字母表$\sum$是一个有穷符号集合,符号包括数字,字母,标点符号…
例如:
- 二进制字母表:{0,1}
- ASCII字符集
- Unicode字符集
字母表的运算
字母表$\sum _{1}$和$\sum _{2}$的乘积
$\sum _{1} \sum _{2}$={ab|a$\in \sum _{1},b \in \sum _{2}$}
例如:{0,1} {a,b} = {0a,0b,1a,1b}
字母表$\sum$的n次幂
\[\begin{equation} \begin{cases} \sum ^0=\{\epsilon\} \\ \sum ^n=\sum ^{n-1}\sum, x\geq1 \end{cases} \end{equation}\]例如:{0,1}$^3$={0,1} {0,1} {0,1} = {000,001,010,011,100,101,110,111}
字母表的正闭包运算
$\sum^+$=$ \sum $ U $ \sum ^2$ U $ \sum^3$U…
例如:{a,b,c,d}$^+$={a,b,c,d
aa,ab,ac,ad,ba,bb,bc,bd…
aaa,aab,aac,aad,…}
即是长度为正数的符号串构成的集合
字母表的克林闭包
$ \sum^*$=$ \sum^0 $ U $ \sum $ U $ \sum ^2$ U $ \sum^3$U…
例如:{a,b,c,d}$^*$={$\epsilon$,a,b,c,d
aa,ab,ac,ad,ba,bb,bc,bd…
aaa,aab,aac,aad,…}
就是在正闭包的基础上添加一个空串。
串
设$\sum $是一个字母表,$ \forall x \in \sum^*$,则称x是$ \sum$上的一个串,串是字母表中的一个有穷序列。
串s的长度,通常记作|s|,指的是s中符号的个数。|$\epsilon$|=0
串的运算
串的连接运算
串x和y的连接指的是把y附加到x后形成的串,记作xy
$\epsilon$s=s$\epsilon$=s
设有x,y,z三个串,如果x=yz,则称y是x的前缀,z是x的后缀。
串s的幂运算
\[\begin{equation} \begin{cases} s ^0=\epsilon\ \\ s ^n=s ^{n-1}s, n\geq1 \end{cases} \end{equation}\]即:串s的n次幂是将n个s连接起来
什么是文法
先通过下面一个简单用来描述英语规则的文法的例子来了解一下文法。
<句子> —> <名词短语> <动词短语> <名词短语> —> <形容词> <名词短语> <名词短语> —> <名词> <动词短语> —> <动词> <名词短语> <形容词> —> little <名词> —> boy <名词> —> apple <动词> —> eat
上面定义了一个简单的句子语法。上面没有用尖括号<>括起来的部分表示语言的基本符号
用尖括号括起来的部分表示语法成分
下面给出文法的形式化定义
文法的形式化定义
G = (V$_T$,V$_N$,P,S)
V$_T$:终结符集合: 是文法定义语言的基本符号,有时也称为token
例如:V$_T$={little,boy,apple,eat}
V$_N$:非终结符集合:是用来表示语法成分的符号,有时也称为“语法变量”
例如:V$_N$={<句子>,<名词短语>,<动词短语>...}
注:V$_T \bigcap$ V$_N$ = $\emptyset$ V$_T \bigcup$ V$_N$ = 文法符号集
P:产生式集合:描述了将终结符和非终结符组合成串的方法。
产生式的一般形式
$\alpha$ —> $\beta$
$\alpha \in$(V$_T \bigcup$ V$_N$)$\ ^+$,而且$ \alpha$至少包含V$_N$中的一个元素,称为产生式的头或左部
$\beta\in$(V$_T \bigcup$ V$_N$)$\ ^*$,称为产生式的体或者右部
例如:P = {<句子> —> <名词短语> <动词短语>,
<名词短语> —> <形容词> <名词短语>,
<动词短语> —> <动词> <名词短语>..... }
S:开始符号 开始符号表示的是该文法中最大的语法成分
例子:S = <句子>
一般文法的表述形式

产生式的简写
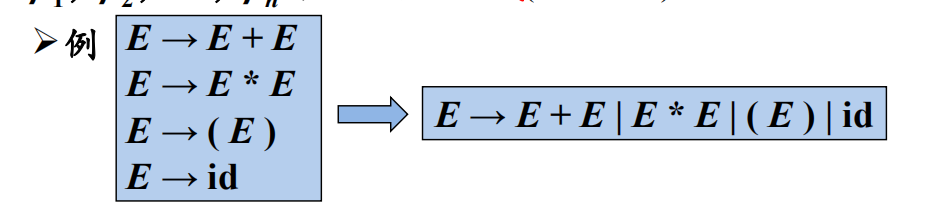
推导和归约

归约就是推导的逆过程。
句子和句型
如果S => $ ^* \alpha , \alpha \in (V _T U V _N)^*$,则称$ \alpha$是G的一个句型
一个句型中既可以包含终结符,也可以包含非终结符,也可能是空串
如果S => $ ^* \omega, \omega \in (V _T U V _N) ^*$,则称$\omega$是G的一个句子
句子是不包含非终结符的句型
例子:

语言的形式化定义
由文法G的开始符号S推导出的所有句子构成的集合称为文法G生成的语言,记为L(G)
即:L(G) = {$ \omega |S=>^* \omega, \omega \in V_T^*$}
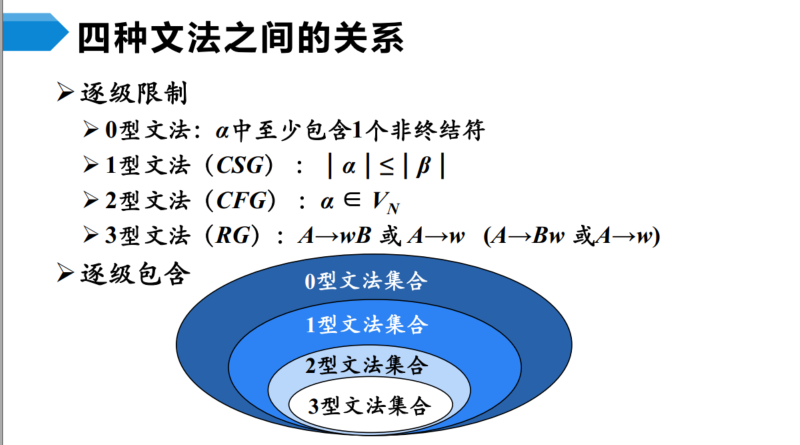
文法的类型
0型文法

1型文法
在0型文法的基础上,规定了产生式左部符号的个数不能超出右部符号的个数
由于$ \alpha$至少包含一个非终结符,所以$\alpha$的长度至少为1,因此$ \beta$的长度至少为1,因此$\beta$不可能是空串。

2型文法
2型文法规定产生式的左边必须是非终结符。

上面这个例子,所有产生式的左部都是非终结符,因此该文法是一个2型文法。
3型文法
又称为正则文法,正则文法包括下面两种
右线性文法
在2型文法的基础上,对产生式的右部进行了限制,每一个产生式形式如下
A—>$\ $$\omega$B或者A—>$\omega$
左线型文法
在2型文法的基础上,对产生式的右部进行了限制,每一个产生式形式如下
A—>B$\ $$\omega$或者A—>$\omega$
例子:

四种文法的关系