什么是编译
编译就是把高级语言或者汇编语言翻译成机器语言的过程
编译器是如何进行编译的
编译器进行编译的过程可以参考人类语言的翻译。
以英语翻译成汉语来说
In the room , he broke a window with a hammer.
编译的过程和翻译过程很相似,都是由源于以翻译成目标语言,过程大致如下
 通过分析源语言来获得句子语言的过程称之为语义分析
通过分析源语言来获得句子语言的过程称之为语义分析
语义分析是如何进行分析的呢?一般是从划分句子成分入手,抓住句子核心的谓语动词,上面句子的谓语动词是broke打破,一提到这个动作,我们就想知道是谁打破了,谁是被打破的对象,用什么打的,为什么打,打的结果如何等等。这些都可以通过broke的上下文来分析得出。
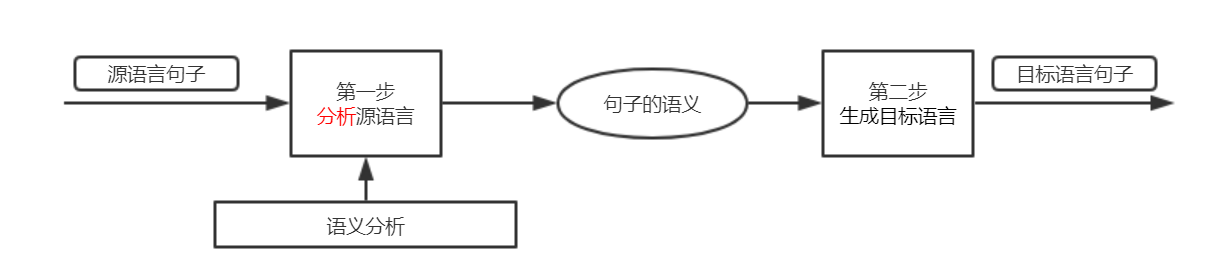
如何进行划分句子成分呢?关键是识别出句子中的各类短语。例如,主语和宾语是由名词短语构成,状语或补语通常是由介词短语构成的,等等。这一过程叫做语法分析(也成为句法分析)。
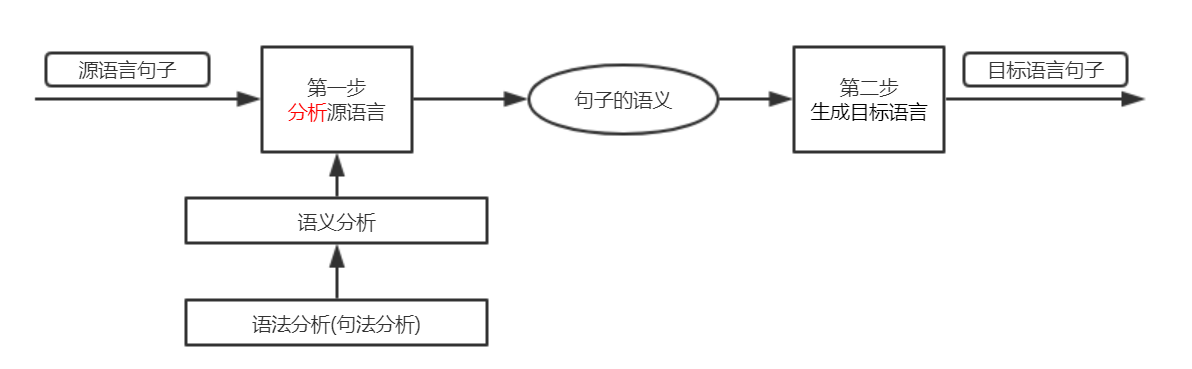
如何进行语法分析呢?关键是要确定出句子中各个单词的词性。例如,一个冠词和一个名词构成一个名词短语,一个代词本身也能构成一个名词短语,等等。这一过程叫做词法分析。
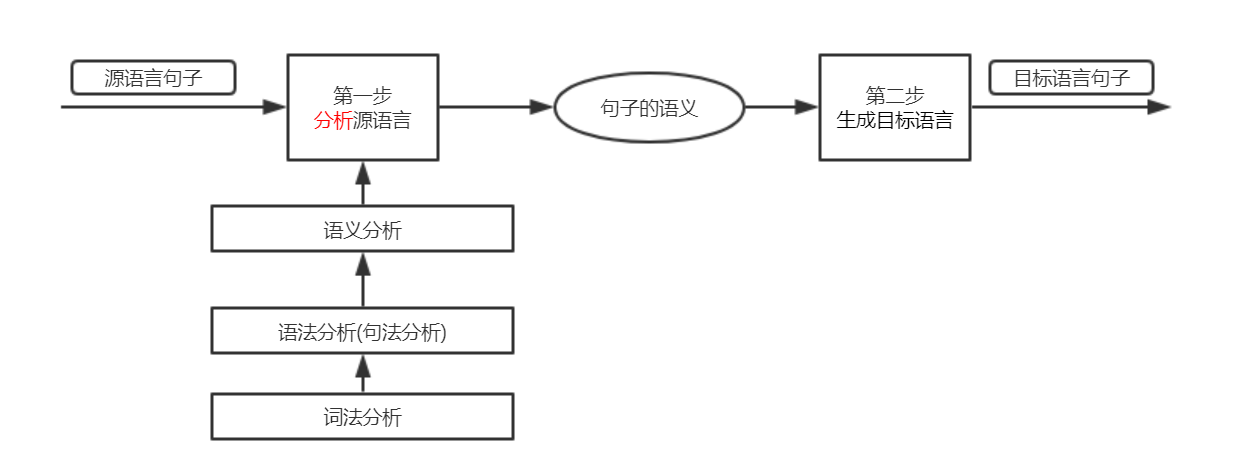
综上,一条句子的翻译过程是这样的:先通过词法分析,分析出句子中各个词语的词性,接着通过语法分析,分析出句子中的各类短语,从而获得句子的结构,接下来通过语义分析,根据句子的结构分析出各个短语在句子中充当什么成分,从而分析出各个短语之间的关系,最后翻译出结果。
实际上编译器在真正工作的情况中也是和上面的过程是一样的
编译器的结构
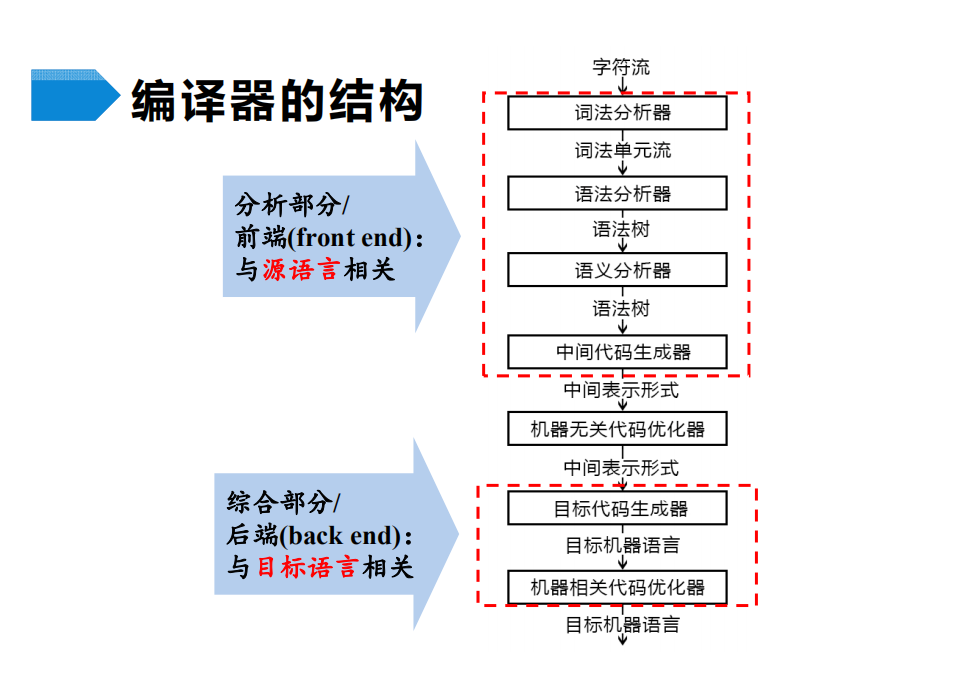
词法分析器的任务
扫描源程序的字符,识别出各个单词,确定单词的类型,将识别出的单词转换成统一的机内表示——词法单元(token)的形式。
token:<种别码:属性值>
| 单词类别 | 种别 | 种别码 | |
|---|---|---|---|
| 1 | 关键字 | if、else | 一词一码 |
| 2 | 标识符 | 变量名、数组名… | 多次一码 |
| 3 | 常量 | 整型、浮点型… | 一型一码 |
| 4 | 运算符 | 算数运算符:+、-、*、/ 关系运算符:>、<、!= 逻辑运算符:&、|、~ |
一词一码 或 一型一码 |
| 5 | 界限符 | ;、{、}、(、)… | 一词一码 |
例子:
while(value != 100) {num++;}
输出:
| 单词 | token |
|---|---|
| while | <WHILE,—> |
| ( | <SLP,—> |
| value | <IDN,value> |
| != | <NE,—> |
| 100 | <CONST,100> |
| ) | <SRP,—> |
| { | <LP,—> |
| num | <IDN,num> |
| ++ | <INC,—> |
| ; | <SEMI,—> |
| } | <RP,—> |
词法分析器如何把代码转换成一个个的token的呢?这个之后会讲到。
语法分析器的任务
将词法分析器中分析输出的token序列中识别出各类短语,并构造语法分析树。
例子:
position = initial + rate * 60 ;
转换成的token序列为:<id,position> <=,—> <id,initial> <+,—> <id,rate> <*,—>,<CONST,60> <;,—>
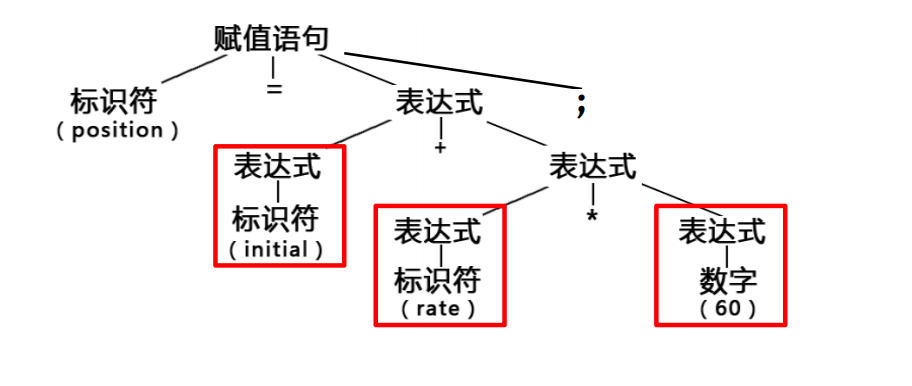
语义分析器的任务
第一个任务是收集标识符的属性信息
- 种属:简单变量,复合变量…
- 类型:int,boolean….
- 存储位置、长度
- 值
- 作用域
- 参数和返回值信息
- 参数个数、参数类型、参数传递方式、返回值类型….
收集到的所有标识符信息都会存放到符号表中。
第二个重要的任务是语义检查,包括变量未经声明就使用、变量重复声明、运算分量类型不匹配、操作符和操作数之间的类型不匹配、函数调用参数数目或类型不匹配、函数返回类型有误等等。
中间代码生成器的任务
中间代码的表示方法有三地址码和语法结构树(简称语法树Syntax Tree,和上面提到的语法分析树parse tree不是同一个内容)
三地址码
三地址码由类似汇编语言的指令序列构成,每个指令最多有三个操作数
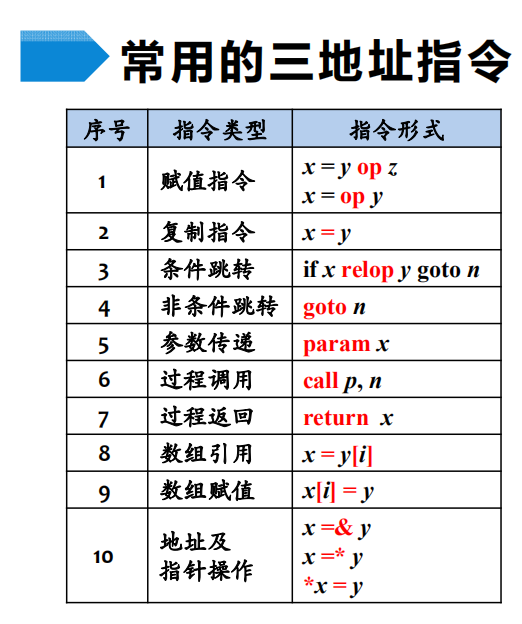
三地址指令的表示形式有以下三种
- 四元式(op,y,z,x) (这里的op指的是原操作符,y,z是操作数,x是目标操作数)
- 三元式
- 间接三元式

中间代码生成的例子
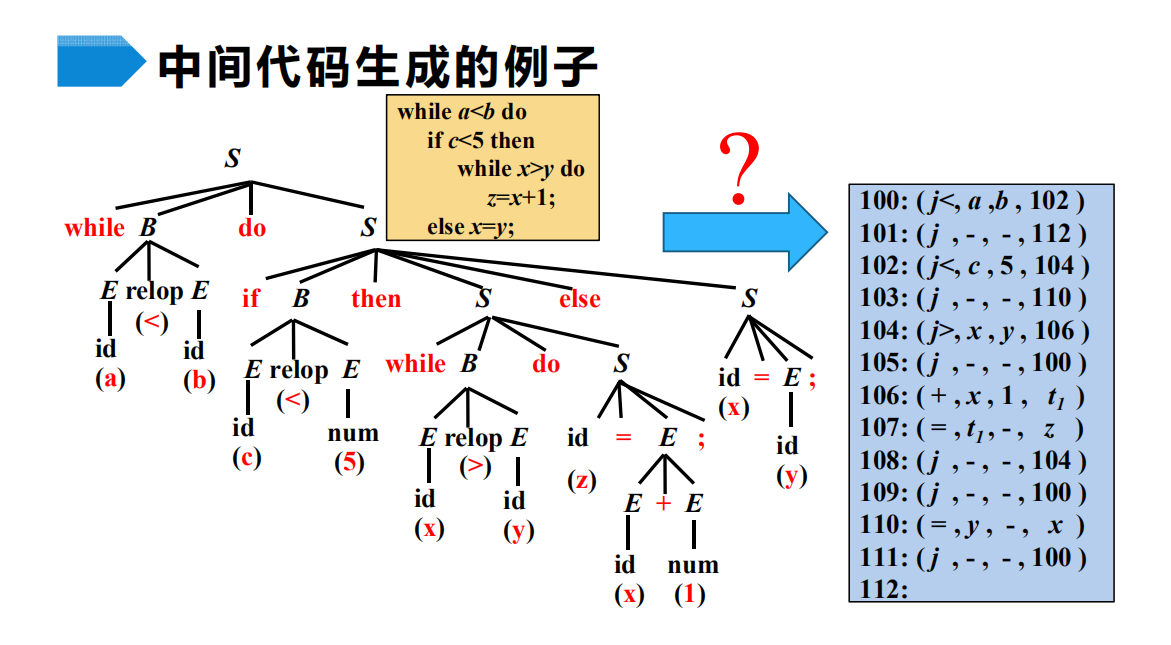
目标代码生成器的任务
目标代码生成器以源程序的中间表示形式(即中间代码生成器的结果)作为输入,映射到目标语言。
目标代码生成器的一个重要任务是为程序中使用的变量合理分配寄存器。
代码优化器的任务
为改进代码进行的等价程序变换,使其运算得快一些,占用空间小一些。
代码优化包括机器无关优化和机器相关优化,机器无关优化在中间代码生成器后进行,机器相关优化在目标代码生成器后执行。
优化的内容包括识别代码中的重复运算或冗余运算,把代价比较大的运算转换成等价的代价比较低的运算等等。